时间:2021-07-01 10:21:17 帮助过:7人阅读
MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数。
什么叫窗口?
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
聚合函数也可以用于窗口函数中,这个后面会举例说明。
下面是一个窗口函数的简单例子:
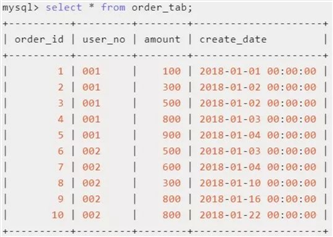
select row_number() over(partition by user_no order by amount desc) as rown_num,order_id,user_no,amount,create_date from order_tab
例子中,row_number()over(partition by user_no order by amount desc)这部分都属于窗口函数,它的功能是显示每个用户按照订单金额从大到小排序的序号。
按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
序号函数:row_number() / rank() / dense_rank() ;分布函数:percent_rank() / cume_dist();
前后函数:lag() / lead(); 头尾函数:first_val() / last_val(); 其他函数:nth_value() / nfile()
窗口函数的基本用法如下: 函数名([expr]) over子句
其中,over是关键字,用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下四种语法来设置窗口:
window_name:给窗口指定一个别名,如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读。上面例子中如果指定一个别名w,则改写如下:
select * from
( select row_number()over w as row_num,
order_id,user_no,amount,create_date
from order_tab
WINDOW w AS (partition by user_no order by amount desc) ) t ;
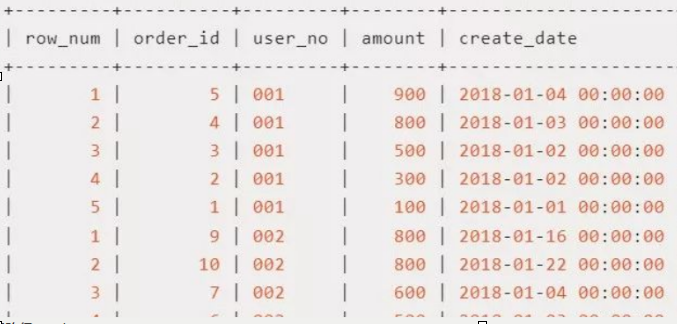
partition子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。上面的例子就按照用户id进行了分组。在每个用户id上,按照order by的顺序分别生成从1开始的顺序编号。
order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition子句配合使用,也可以单独使用。上例中二者同时使用,如果没有partition子句,则会按照所有用户的订单金额排序来生成序号。
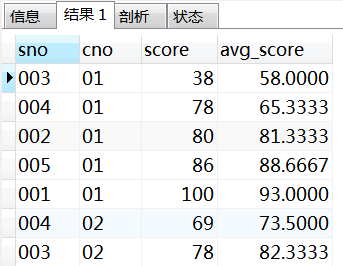
frame子句:frame是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。比如要根据每个订单动态计算包括本订单和按时间顺序前后两个订单的平均订单金额,则可以设置如下frame子句来创建滑动窗口:
select sc.*,avg(score) over w as avg_score from sc window w as (partition by cno order by score rows between 1 preceding and 1 following);
得到
对于滑动窗口的范围指定,有两种方式,基于行和基于范围,具体区别如下:
(1)基于行:通常使用BETWEEN frame_start AND frame_end语法来表示行范围,frame_start和frame_end可以支持如下关键字,来确定不同的动态行记录:
CURRENT ROW 边界是当前行,一般和其他范围关键字一起使用
UNBOUNDED PRECEDING 边界是分区中的第一行
UNBOUNDED FOLLOWING 边界是分区中的最后一行
expr PRECEDING 边界是当前行减去expr的值
expr FOLLOWING 边界是当前行加上expr的值
下面都是合法的范围:
rows BETWEEN 1 PRECEDING AND 1 FOLLOWING 窗口范围是当前行、前一行、后一行一共三行记录。
rows UNBOUNDED FOLLOWING 窗口范围是当前行到分区中的最后一行。
rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 窗口范围是当前分区中所有行,等同于不写。
(2)基于范围:和基于行类似,但有些范围不是直接可以用行数来表示的,比如希望窗口范围是一周前的订单开始,截止到当前行,则无法使用rows来直接表示,此时就可以使用范围来表示窗口:INTERVAL 7 DAY PRECEDING。Linux中常见的最近1分钟、5分钟负载是一个典型的应用场景。
有的函数不管有没有frame子句,它的窗口都是固定的,也就是前面介绍的静态窗口,这些函数包括如下:
CUME_DIST()
DENSE_RANK()
LAG()
LEAD()
NTILE()
PERCENT_RANK()
RANK()
ROW_NUMBER()
接下来我们以上例的订单表为例,来介绍每个函数的使用方法。表中各字段含义按顺序分别为订单号、用户id、订单金额、订单创建日期。
序号函数不再介绍了。 row_number() / rank() / dense_rank()。
分布函数 percent_rank()/cume_dist()。
percent_rank()
用途:和之前的RANK()函数相关,每行按照如下公式进行计算:
(rank - 1) / (rows - 1)
其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
应用场景:没想出来……感觉不太常用,看个例子吧

percent列按照公式(rank - 1) / (rows - 1)带入rank值(row_num列)和rows值(user_no为‘001’和‘002’的值均为5)。
cume_dist()
用途:分组内小于等于当前rank值的行数/分组内总行数,这个函数比percen_rank使用场景更多。
应用场景:大于等于当前订单金额的订单比例有多少。

列cume显示了预期的数据分布结果。
六、前后函数
lead(n)/lag(n)。
用途:分区中位于当前行前n行(lead)/后n行(lag)的记录值。使用场景:查询上一个订单距离当前订单的时间间隔。
select order_id,user_no,amount,create_date,last_date, date_diff(create_date,last_date) as diff from ( select order_id,user_no,amount,create_date,lag(create_date,1) over w as list_date from order_tab window w as (partition by user_no order by create_date) ) t;
得到
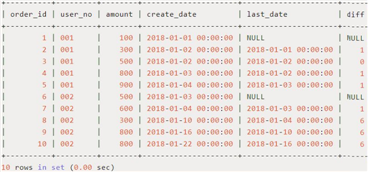
内层SQL先通过lag函数得到上一次订单的日期,外层SQL再将本次订单和上次订单日期做差得到时间间隔diff。
七、头尾函数
头尾函数——first_val(expr)/last_val(expr)。
用途:得到分区中的第一个/最后一个指定参数的值。使用场景:查询截止到当前订单,按照日期排序第一个订单和最后一个订单的订单金额。

结果和预期一致,比如order_id为4的记录,first_amount和last_amount分别记录了用户‘001’截止到时间2018-01-03 00:00:00为止,第一条订单金额100和最后一条订单金额800,注意这里是按时间排序的最早订单和最晚订单,并不是最小金额和最大金额订单。
八、其他函数
其他函数——nth_value(expr,n)/nfile(n)。
nth_value(expr,n)
用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名。
应用场景:每个用户订单中显示本用户金额排名第二和第三的订单金额。

nfile(n)
用途:将分区中的有序数据分为n个桶,记录桶号。
应用场景:将每个用户的订单按照订单金额分成3组。
SQL如下:

此函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到N个并行的进程分别计算,此时就可以用NFILE(N)对数据进行分组,由于记录数不一定被N整除,所以数据不一定完全平均,然后将不同桶号的数据再分配。
九、聚合函数作为窗口函数
用途:在窗口中每条记录动态应用聚合函数(sum/avg/max/min/count),可以动态计算在指定的窗口内的各种聚合函数值。
应用场景:每个用户按照订单id,截止到当前的累计订单金额/平均订单金额/最大订单金额/最小订单金额/订单数是多少?
SQL如下:
select order_id,user_no,amount,create_date,sum(amount) over w as sum1 from order_tab window w as (partition by user_no order by order_id)
除了这几个常用的聚合函数,还有一些也可以使用,比如BIT_AND()、STD()等等,具体查看官方文档。
chapter8 备份与恢复
1. mysqldump 命令
mysqldump把数据库中的数据备份为一个文本文件,表结构与表的数据将存储在生成的文本文件中。
mysqldump 的原理很简单:先查出表结构,再在文本中生成一条create 语句。然后把表中的记录转化为insert 语句。还原数据的时候就是用 create 与insert 来还原表。
mysqldump可以备份一个、多个、所有数据库。
语法:mysqldump -u用户名 -p密码 数据库名 >dump文件的路径和名称
mysqldump -u username -p dbname table1 table2... >backupname.sql
一般备份为sql格式的,也可以是sql格式的。
myqldump不是sql语句,mysqldump是mysql用于转存储数据库的实用程序。
不能在MySQL可视化工具或者DOS里的mysql下直接执行。
其实应该直接在cmd+r打开的窗口直接执行。
备份多个数据库
mysqldump -u username -p --databases dbname1 dbname2... >backupname.sql
备份所有数据库
mysqldump -u username -p --all --databases >backupname.sql
2. 直接复制整个数据库
此时最好停止服务器,保证复制期间没有数据变化。
3.mysqlhotcopy 工具, 这不是mysql自带的,主要安装perl的数据接口包。
4.数据还原 mysql
mysql -u root -p (dbname 可写可不写) <backup.sql
mysql -u root -p <D:\all.sql 恢复所有数据库
5.表的导入导出
导出文本文件
select ... into outfile
select sno from student into outfile‘D:\sno.txt‘ [option]
option有以下几种
fields terminated by ‘字符串‘ , 字段的分隔符,默认是\t
fields enclosed by ‘字符串‘,
fields terminated by ‘字符串‘
lines starting by ‘‘ , 每行开头的字符 ,默认没有
lines terminated by‘‘ 每行的结束符,默认是\n
SELECT sno,sname FROM student INTO OUTFILE ‘D:\info.txt‘ FIELDS TERMINATED BY ‘\、‘
LINES STARTING BY ‘\>‘ TERMINATED BY ‘\r\n‘
导入文本文件
load data infile ‘文件路径‘ into table student
fields terminated by‘\t‘ lines terminated by‘\r\n‘ ignore 1 lines
create table student2 like student; SELECT * FROM student INTO OUTFILE ‘D:\info2.txt‘ FIELDS TERMINATED BY ‘\、‘ LINES STARTING BY ‘\>‘ TERMINATED BY ‘\r\n‘; load data infile ‘D:\info2.txt‘ into table student2 FIELDS TERMINATED BY ‘\、‘ LINES STARTING BY ‘\>‘ TERMINATED BY ‘\r\n‘
能不能导入数据到表的某些字段中?而不是全部。
chapter9 mysql优化查询
1.分析查询语句 explain 或者desc select 语句;
explain select * from student;

rows表示返回查询结果所检验的行数。
可以去看看用了索引查询速度的变化。上述如果对 sdept 建立了索引


发现rows变成了5。
并不是说加了索引查询都会提高。
(1) where name like ‘%好‘, 开头就是%, 即使name 加了索引也没用;
(2)用了or 两个条件必须同为索引,否则不会使用索引进行查询。
2. 优化数据库结构
如果一个字段很多但是使用频率低,那么可以把它分解为多个表。
如果两张表的部分字段用的很多,可以建立一张中间表,以后都在中间表里进行查询,不用去关联这两张原表了。
3. 优化插入记录的速度。
插入记录时,索引、唯一性校验都会影响插入记录的速度。一次插入多条数据和多次插入记录的速度都不同。
(1)禁用索引 alter table 表名 disable keys;
重启索引 alter table 表名 enable keys;
(2)禁用唯一性检查。
mysql会检查插入的记录。
禁用唯一性 set unique_checks=0; 启用唯一性 set unique_checks=1;
4. 优化insert 语句
insert into student values(‘001‘,‘CC‘, ‘02’,‘PC‘),(‘002‘,‘CD‘, ‘02’,‘PC‘) 这种比单独的一条条insert 更快。
最好用load data infile 速度较快。
MySQL(2): 窗口函数\备份与恢复\性能优化\权限管理
标签:工具 大于 ast 多次 dep base lag rgb partition