时间:2021-07-01 10:21:17 帮助过:12人阅读
MySQL启动服务:
1、cmd -- >services.msc -->本地服务
2、管理员身份打开cmd
SQL分类(Structured Query Language):结构化查询语言
DDL:操作数据库、表:CRUD
操作库:CRUD
1、C(Create):创建
create database if not exists mydatabase character set utf8;
2、R(Retrieve):查询
#查询所有数据库名称: show databases; #查询某个数据库创建语句: show create database mydatabase;
#查询当前正在使用的数据库
select database();
#使用数据库
use mydatabase;
3、U(Update):修改
#修改数据库字符集 alert database mydatabase character set GBK;
4、D(Delete):删除
drop database if exists mydatabase;
操作表:CRUD
1、C(Create):创建
create table student( id int, name varchar(20),
age int,
score double(4,2)
);
#最后一列不需要加逗号
#复制表
create table student like stu;
主要数据类型:
2、R(Retrieve):查询
#查询某个数据库所有表名称 show tables; #查询表结构 desc student;
3、U(Update):修改
#修改表名 alter table stu rename to student; #修改字符集 alter table student character set GBK; #添加一列 alter table student add hobby varchar(10); #修改列名称 类型 alter table student change score lesson varchar(10); alter table student modify score varchar(10); #删除列 alert table student drop hobby;
4、D(Delete):删除
drop table if exists student;
DML:增删改表中数据
1、添加数据:
insert into student(id,name,age,score)values(1,‘周杰伦‘,18,98.5);
#表名后不定义列名:
insert into student(2,‘五月天‘,17,97.8);
2、删除数据
delete from student where id = 1; #如果不加条件会删除表中所有记录,此时推荐用truncate truncate table student; #delete与truncate二者之间的区别 -- 有多少条记录就会执行多少次删除操作 -- 先删除表,然后再创建一张一样的(清空表)
3、修改数据:
update student set name = 王力宏,age = 19 where id =1;
DQL:查询表中记录
select * from student;
1、语法:
select 字段 from 表名 where 条件 group by 分组 having 分组之后条件 order by 排序 limit 分页限定
2、基础查询:
select name,age from student; -- *代表查询所有字段,不推荐使用 -- 去重:distinct (两个字段有一个字段相同是不能去的) select distintct score from student;
3、条件查询
-- where子句后跟条件 -- 运算符 /* >、<、<=、>=、=、<> between...and in like模糊查询 占位符: _:单个任意字符 %:多个任意字符 is null and or not */
4、排序查询
select * from student order by score desc; --ASC:默认 DESC:降序
5、聚合函数
SELECT COUNT(id) FROM student; SELECT MAX(score) FROM student; /* max:计算最大值 min:计算最小值 sum:计算和 avg:计算平均值 */
7、分组函数
/* 分组函数: 语法:group by 分组字段(聚合函数) having与where的区别: 1.where在分组之前限定,如果不满足条件,不参与分组,having在分组后限定,如果不满足条件,则不会被查询 2.where后不可以用聚合函数,having后可以用聚合函数进行判断 */ SELECT sex , AVG(math),COUNT(id) FROM student3 GROUP BY sex; SELECT sex,AVG(math),COUNT(id) FROM student WHERE math>20 GROUP BY sex; SELECT sex,AVG(math),COUNT(id) FROM student3 WHERE math>10 GROUP BY sex HAVING COUNT(id)>3;
8、分页查询
/* 分页查询: 语法:limit 开启的索引,每页显示条数 开始索引:当前页码-1 * 每页显示的条数 */ select * from student limit 0,3 --第一页 select * from student limit 3,6 --第二页
对表中数据进行限定,保证数据的完整性,正确性,有效性
分类:
--非空约束:not null,值不能为空 --1.创建表时添加约束 create table student( id int, name varchar(20) not null -- name为非空 ); --2.创建表后,添加非空约束 alert table student modify name varchar(20) not null; --3.删除name的唯一约束 alert table student modify name varchar(20);
--唯一约束:unique,值不能重复 --1.创建表时添加唯一约束 create table student( id int, id_card varchar(20) unique -- 添加唯一约束 -- 注意mysql中,唯一约束限定的列的值可以有多个null ); --2.创建表后添加唯一约束 alter table student modify id_card varchar(20) unique; --3.删除唯一约束 alert table student drop index id_card;
/*主键约束:primary key 1.非空且唯一 2.一张表只能有一个主键,相当于表中记录唯一标识 */ -- 创建表时添加主键约束 create table student( id int primary key -- 给id添加主键约束 name varchar(20) ); -- 创建完表后添加主键 alter table student modify id int primary key; -- 删除主键 alert table student drop primary key;
-- 自动增长 -- 如果某列是数值类型,可使用auto_increment完成自动增长 -- 在创建表时,添加主键约束,并且完成主键自增长 create table student( id int primary key auto_increment,-- 给id添加主键约束 name varchar(20) ); -- 删除自动增长 alter table student modify id int; -- 添加自动增长 alter table student modify id int auto_increment;
/*外键约束:foreign key,让表与表产生关系,从而保证数据的正确性。 1. 在创建表时,可以添加外键 语法: create table 表名( .... 外键列 constraint 外表名称 foreign key (外键列名称) references 主表名称(主表列名称) ); 2. 删除外键 ALTER TABLE 表名 DROP FOREIGN KEY 外键名称; 3. 创建表之后,添加外键 ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称); */ CREATE TABLE department( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) NOT NULL, description VARCHAR(100) ); CREATE TABLE employee( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10) NOT NULL, gender VARCHAR(2) NOT NULL, salary FLOAT(10,2), age INT(2), gmr INT, dept_id INT, CONSTRAINT fk_emp FOREIGN KEY(dept_id) REFERENCES department(id) );
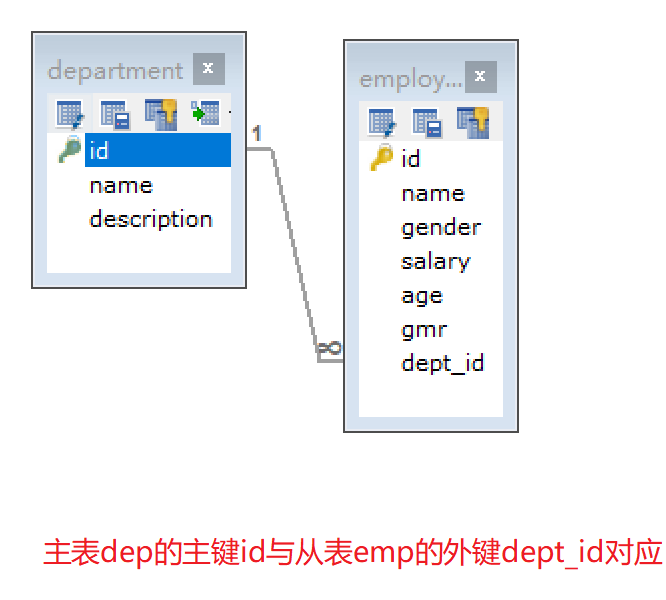
-- 删除外键 -- 可以通过 show create table employee;查看外键名 alter table employee drop foreign key fk_emp; -- 创建表后添加外键 ALTER TABLE employee ADD CONSTRAINT fk_emp FOREIGN KEY (dept_id) REFERENCES department(id);
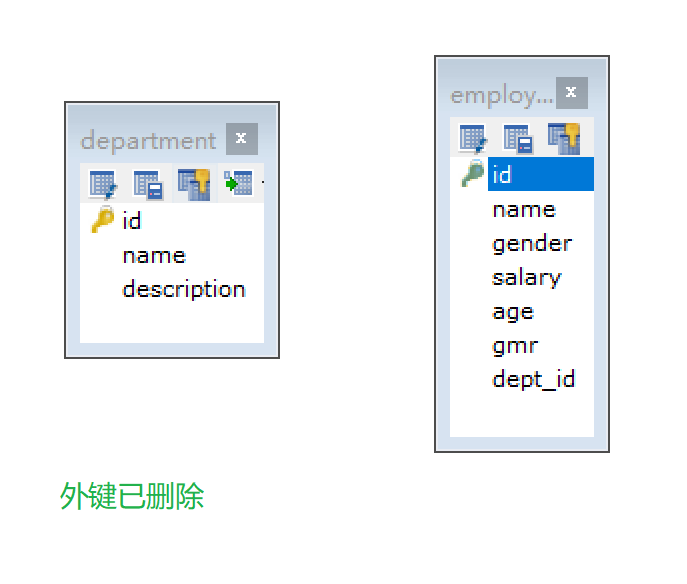
/*级联操作:启用级联后,更新一个表的主键值,系统会相应地更新所有匹配的外键值 添加级联操作 语法:ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE ; 分类: 1. 级联更新:ON UPDATE CASCADE 2. 级联删除:ON DELETE CASCADE */
1、表与表之间的关系
1)一对一 人和身份证 -- >一个人只能有一个身份证
2)一对多或多对一 -- >一个班级有多个学生,一个学生只能对应一个班级
3)多对多 -- >一个人可以有很多兴趣爱好,一个 兴趣爱好也可以被多个人所选择
2、实现方式
一对多(多对一):在多的一方建立外键,指向一的一方主键
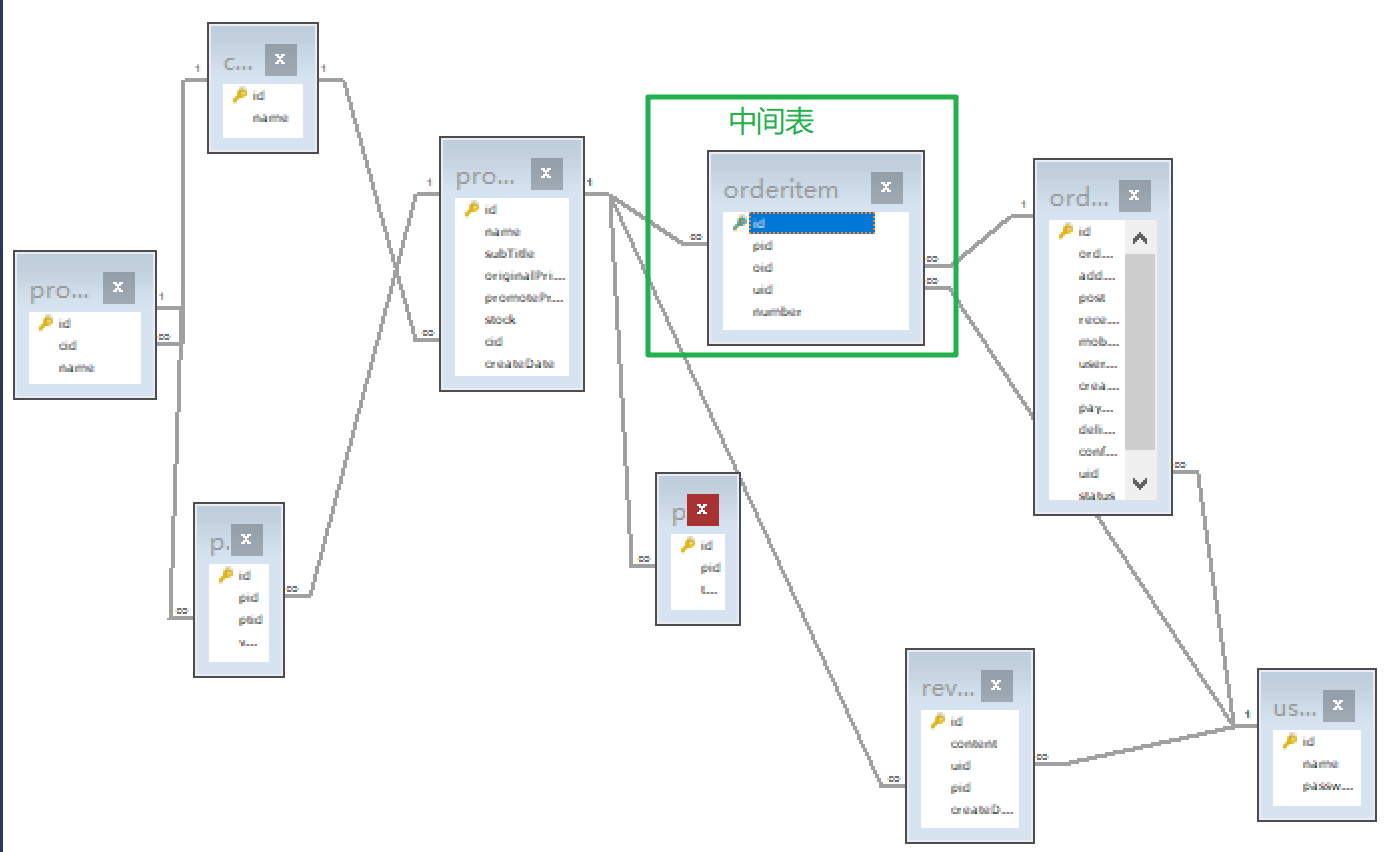
多对多:需要借助于第三张中间表才能实现多对多的关系。中间表至少有两个字段,用来作为第三张表的外键,分别指向两张表的主键
如图,订单项表(Orderitem)作为中间表
2、数据库设计范式
目前关系数据库设计范式一共有六种,现在主要理解前面三种
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
第一范式:每一列都是不可分割的原子项(数据库中表的每一列不能再分,这是构成数据库表的基础。
第二范式:在1NF的基础上,属性完全依赖于主键,消除部分依赖
第三范式:在2NF的基础上,任何非主属性不依赖于其它非主属性,消除传递依赖,
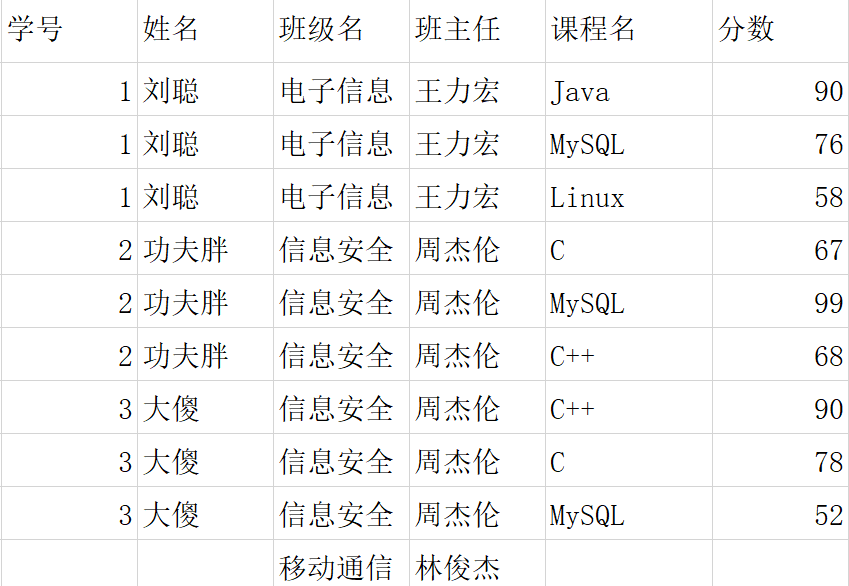
该表属于第一范式,不难发现1NF存在很多问题
1、数据冗余:
2、数据无法添加:
3、数据不能删除:
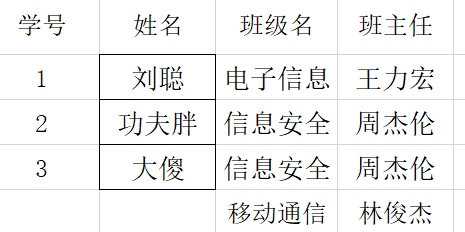
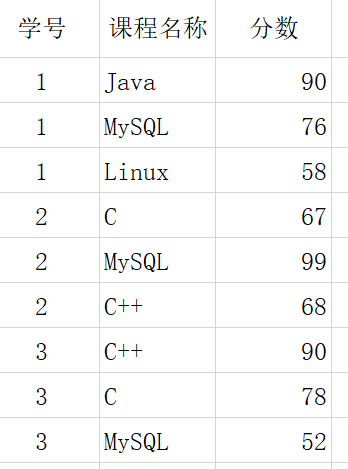
第二范式:将第一范式的一张表拆分为学生表和选课表,虽然解决了第一条,但后面两条问题依然不能解决
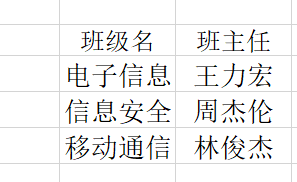
此时,只需要将学生表中的班主任和班级抽取出一张班级表就可以完美的解决后面两个问题了,这就是第三范式
解释一下:部分函数依赖和传递函数依赖,首先说一下函数依赖和完全函数依赖
姓名可以通过学号来确定,这就是函数依赖
学号和课程名都需要与学生分数对应,这就是完全函数依赖(当然也属于函数依赖)
部分函数依赖就是两个或两个以上的参数部分与另外一个参数对应,例如:(学号,课程名)--姓名
传递函数依赖就是通过A确定B,再通过B确定C,则可以称C传递于函数A。例如:(学号-->班级名,班级名-->班主任)
码:如果在一张表中,一个属性或属性组(两个或以上的属性),被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如:该表中码为:(学号,课程名称)
主属性:码属性组中的所有属性
非主属性:除过码属性组的属性
总结如下:
第一范式:每个列都是不可分割的原子项
第二范式:在1NF的基础上,消除部分函数依赖,也就是说非码属性必须完全依赖于码(属性完全依赖于主键)
第三范式:在2NF的基础上,消除传递依赖,任何非主属性不依赖于其它非主属性(如果主属性不依赖于其他非主属性,则不符合第三范式)
数据库备份与还原
备份: mysqldump -u用户名 -p密码 数据库名称 > 保存的路径
mysqldump -uroot -p123456 db1 > e://a.sql
还原:source 文件路径
source e://a.sql
MySQL一
标签:兴趣爱好 推荐 cad creat 图片 之间 自动增长 运算符 关系数据库