时间:2021-07-01 10:21:17 帮助过:10人阅读
create table score ( `id` int unsigned primary key auto_increment, `math` float not null default 0, `english` float not null default 0 ) charset=utf8; insert into score (`math`, `english`) values (49, 71), (62, 66.7), (44, 86), (77.5, 74), (41, 75), (82, 59.5), (64.5, 85), (62, 98), (44, 36), (67, 56), (81, 90), (78, 70), (83, 66), (40, 90), (90, 90);
select rand(); -- 随机数 select unix_timestamp(); -- 显示Unix时间戳 select id, name from student;
SELECT student.name, score.math FROM student, score;
select name from student where city = ‘上海‘;
select `name` from `student` where `description` is null; select `name` from `student` where `description` is not null;
select id, math from score where math between 60 and 70; select id, math from score where math not between 60 and 70; select * from score where math>=80 and english<=60; -- 直接做比较判断
select `name`, `birthday` from `student` where `birthday` > ‘1995-1-1‘; select `name`, `birthday` from `student` having `birthday` > ‘1995-1-1‘; select * from student where id>=3 and city=‘北京‘; select * from student having id>=3 and city=‘北京‘; select * from student where id>=3 having city=‘北京‘; -- 混用
但是他们也有区别。
select `name`, `birthday` from `student` where id > 2; -- 报错,having的条件查询,只能包含在前面的搜索结果里 select `name`, `birthday` from `student` having id > 2;
select name as n,birthday as b,id as i from student having i > 2; -- 报错,where只识别存在的字段 select name as n,birthday as b,id as i from student where i > 2; -- 取出每个城市中满足最小出生年份大于1995的 select city, group_concat(birthday) from student group by city having min(birthday) > ‘1995-1-1‘;
select sex, count(id) from student group by sex; -- 在group将需要的结果通过 “聚合函数” 拼接 select sex, group_concat(name) from student group by sex;
select * from student order by age; select * from student order by age desc; select city,avg(money),group_concat(name),sum(money) from student group by city having sum(money)>70 order by sum(money);
语法:
select 字段 from 表名 limit m; -- 从第 1 行到第 m 行 select 字段 from 表名 limit m, n; -- 从第 m 行开始,往下取 n 行 select 字段 from 表名 limit m offset n; -- 跳过前 n 行, 取后面的 m 行
示例:
select distinct city from student;
dual 是一个虚拟表, 仅仅为了保证 select ... from ... 语句的完整性
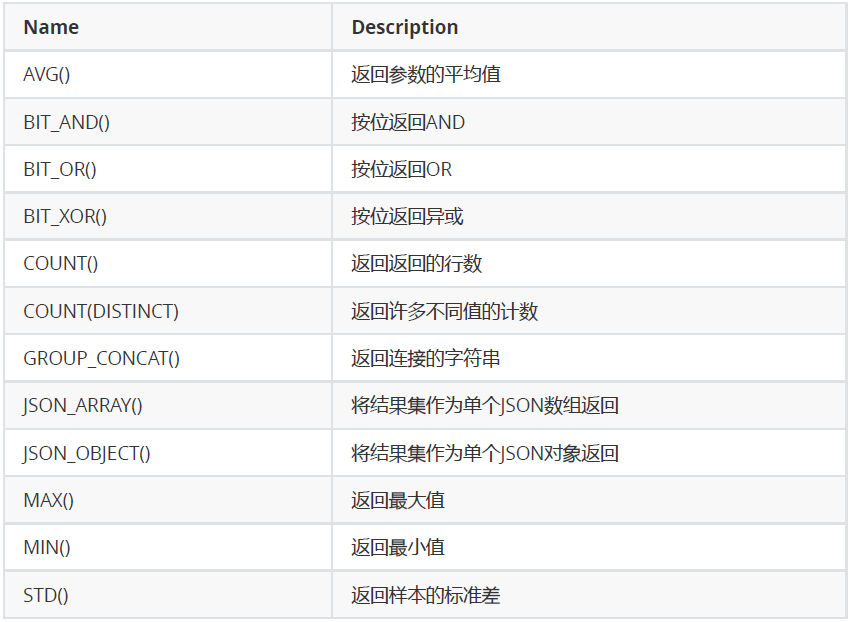
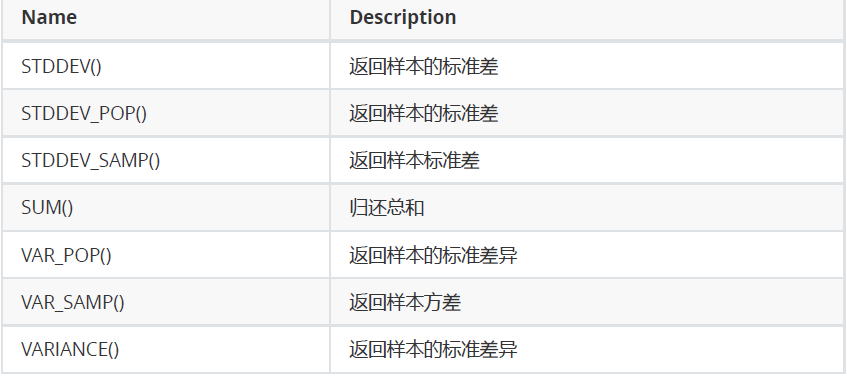
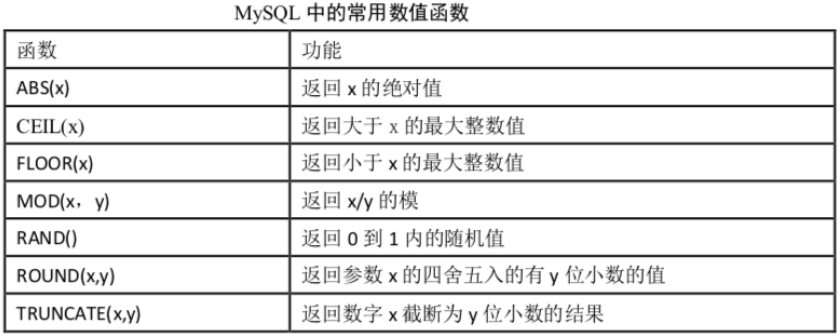
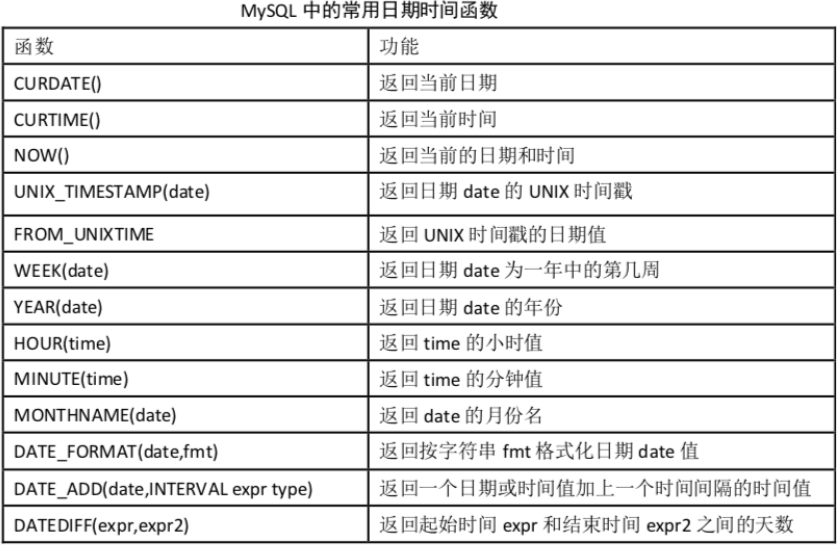
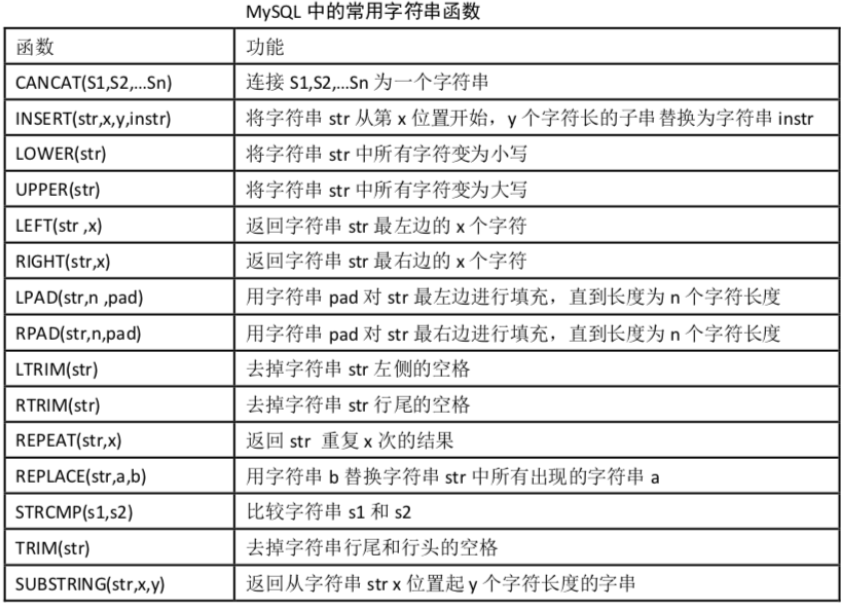
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
union要求:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
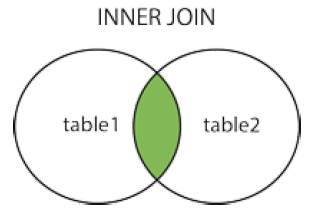
SELECT 字段 FROM 表1 INNER JOIN 表2 ON 表1.字段=表2.字段; -- 或: SELECT column_name(s) FROM table1 JOIN table2 ON table1.column_name=table2.column_name;
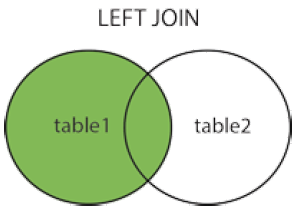 LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
语法
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name=table2.column_name; -- 或: SELECT column_name(s) FROM table1 LEFT OUTER JOIN table2 ON table1.column_name=table2.column_name;
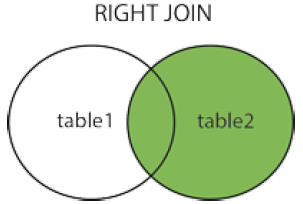
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
语法
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name=table2.column_name; -- 或: SELECT column_name(s) FROM table1 RIGHT OUTER JOIN table2 ON table1.column_name=table2.column_name;
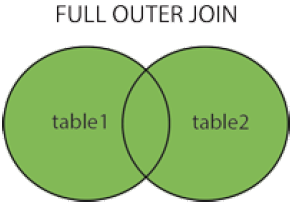
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
查询的语句中还有一个查询
select name from student where id in (select id from score where math > 10);
create view v_user_score as select a.id, a.name, b.math, b.english from student a inner join score b on a.id=b order by id; -- 查询 select * from v_user_score; -- 删除 drop view v_user_score;
数据库的查询
标签:随机数 out outer nbsp span 学生 输出 情况下 判断