时间:2021-07-01 10:21:17 帮助过:23人阅读
本文稍微有点晦涩、但是看过之后你就能Get到MySQL的崩溃恢复到底是怎么做的!
文章公号 首发!连载中!关注微信公号回复:“抽奖” 还可参加抽??活动
在这篇文章之前,白日梦跟你分享了什么是redo log、以及redo log的作用、redo log的刷盘机制等知识点。简单来说就是redo log是MySQL的事物日志。比如你执行一条update语句,在你提交事物之前MySQL就会在redo log中记录下你这条SQL对XXX表空间XXX数据页的XXX偏移量做了XXX更新。
为什么在你当update时,事物提交之前先不断的写redo log呢?
如果你看过白日梦前面介绍buffer pool的文章,这个问题的答案想必你也能很快的想出来:MySQL为了提高性能,你对它数据行的增、删、改操作其实都优先发生在内存(Buffer Pool)中。那你想,假如你update了某些数据,Buffer Pool中的数据页也就会被你改成脏数据页。那万一你刚修改完并提交了事物,还没来得及将数据落盘MYSQL就宕机了怎么办?
当MySQL重启的时候需要把方才修改的内容恢复出来吧,不然数据就不一致了。那怎么恢复呢?就借助redo log恢复。因为前面说了,当你begin事物开始操作时,会先写redo log,在操作数据页。这个数据恢复的过程也叫做重做。
随着MySQL的运行,Buffer Pool中的数据页会被修改成脏数据页,当你开启事物进行一系列的操作时MySQL会为你不停的记录一堆日志,拿redolog来说,rodo log也是需要往先往内存中写,再以块的形式刷新回磁盘。
无论怎样都会存在这样一个中间过程:内存中存在脏数据页、和脏日志未来得及刷新回磁盘。
而本小节中要说的Checkpoint机制就是将这些脏数据刷新回磁盘的机制,即只要发生Checkpoint,就要将脏数据刷新回磁盘,反过来,当MySQL重启时会去找Checkpoint,并且根据Checkpoint的特性。MySQL可以明确的知道checkponit之前的脏数据已经落过盘了,重启时没必要进行重做。
看到这里你已经大概知道Checkpoint是什么了。我们在稍微总结一下Checkpoint机制的作用:
1、所谓的崩溃恢复,其实就是MySQL重启时照着redo log中的最后一次Checkpoint之后的日志回放一遍
2、因为Checkpoint会不断的更新,并且MySQL重启时只需要对Checkpoint之后的数据进行恢复,所以Checkpoint会缩短MySQL重启的时间。
3、因此每次进行Checkpoint时buffer pool中的脏数据页、redo log中的脏日志都会落盘。所以Checkpoint实际上起到了为这两者进行瘦身的作用。维持两个的可用性。
有两种:Checkpoint
1、Sharp(急剧的) Checkpoint
触发时机:比如当MySQL关闭时,或者是切换要写的redo log时,会一次性将所有的脏日志全部刷新到磁盘中,这种模式下会对MySQL的性能带来较大的影响。
2、Fuzzy(模糊的) Checkpoint
这种模式下的Checkpoint每次仅将部分脏日志刷新到磁盘中
触发条件1:Master Thread Checkpoint
由master线程控制,每秒或每10秒刷入一定比例的脏页到磁盘。
触发条件2:FLUSH_LRU_LIST Checkpoint
从MySQL5.6开始可通过 innodb_page_cleaners 变量指定专门负责脏页刷盘的page cleaner线程的个数,该线程的目的是为了保证lru列表有可用的空闲页。
触发条件3:async/sync flush Checkpoint
同步刷盘还是异步刷盘。例如还有非常多的脏页没刷到磁盘,这时候会选择同步刷到磁盘,但这很少出现;如果脏页不是很多,可以选择异步刷到磁盘,如果脏页很少,可以暂时不刷脏页到磁盘
触发条件4:dirty page too much Checkpoint
脏页太多时强制触发检查点,目的是为了保证缓存有足够的空闲空间。too much的比例由变量 innodb_max_dirty_pages_pct 控制,MySQL 5.6默认的值为75,即当脏页占缓冲池的百分之75后,就强制刷一部分脏页到磁盘。
LSN全称是:log sequence number。
关于什么是LSN没什么难以理解的,它就是一个序列号。并且表空间中的数据页、缓存页、内存中的rodo log、磁盘中的redo log以及checkponit都有LSN标记。
LSN又啥用呢?比如MySQL重启时会对比数据页的LSN和redo log的LSN的大小,如果前者的LSN比后者小。说明数据页中缺失了一部分数据。如果满足其他数据恢复的条件,MySQL就会将LSN之后的这些redo 进行一次回方,完成数据的恢复。
举个需要重做的例子:假设你使用的是MySQL集群,从库通过binlog同步主库的数据。
理论上:你开启了事物,然后一顿操作然后提交事物。在你操作的过程中MySQL会为你记录undo log、redo log parpare、binlog、redo log commit。(两阶段提交)
然而不幸的是,当MySQL写完binlog、且未来得及写 redo log commit完成的事物最终的提交就挂了。
那MYSQL重启,由于未来得及commit,脏数据页没有刷新到磁盘上,所以重启时得到的数据时不准确的,但是,实际上MySQL会根据方才的redo log重做。因为binlog已经写完了,那就意味着从库已经完成了数据的同步。如果它不重做的话,它相对于从库就缺失了一部分数据,导致主从数据不一致。
关于这个例子,后面的文章中我还会非常详细的说。
当然关于LSN你还得了解:
在MySQL 5.6.3之前,LSN是一个4字节的无符号整数。当重做日志文件的大小限制从4GB增加到512GB时,由于需要额外的字节来存储额外的大小信息,因此LSN在MySQL 5.6.3中变成了8字节的无符号整数。
你可以执行如下SQL查看你的MySQL的LSN标记记录情况:
show engine innodb status\G

为了更彻底的理解LSN、checkpoint我们可以一起看下面几张图:
第一张:我去网上找讲LSN的帖子时发现的很多文章使用下面这张图
但是这张图的中我用方框圈出来的地方实际上搞错了。图中的LSN应该放在倒数第二条线上。
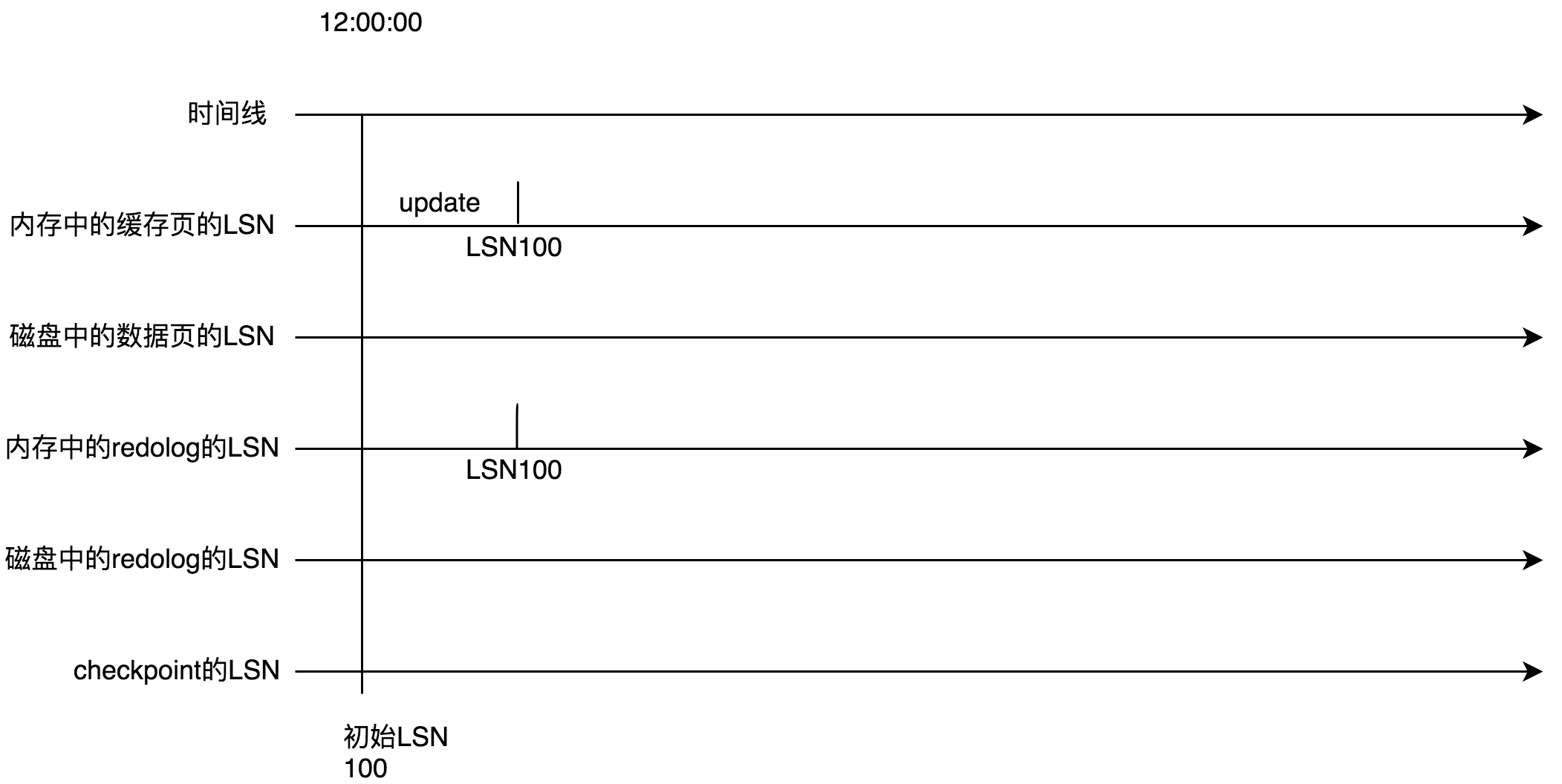
我参照上图模改一套版图、简述一下表达的意思如下:

前面说了表空间中的数据页、内存中的缓存页、内存中的redo log、磁盘中的redo log、checkpoint它们五者都有记录LSN。所以你可以看到,在12:00:00时刻,它们五者中的LSN都是100。
然后在12:00:00时刻你开启了一个事物,执行update语句,之前的文章说过,你的CRUD都优先发生在内存中,也就是buffer pool中。并且在修改内存中的数据前先记录redo log,所以buffer pool中的缓存页和内存中的redo log的LSN率先被更新成110。

紧接着你的事物中又执行了delete语句,同样的道理内存中的redo log和缓存页的LSN被更新为150。接着时间来到了12:00:01。触发了由参数innodb_flush_log_at_timeout(默认1s)redo log刷盘机制。redo log会部分落盘,所以上图中的磁盘上的redo log的lSN更新为150。
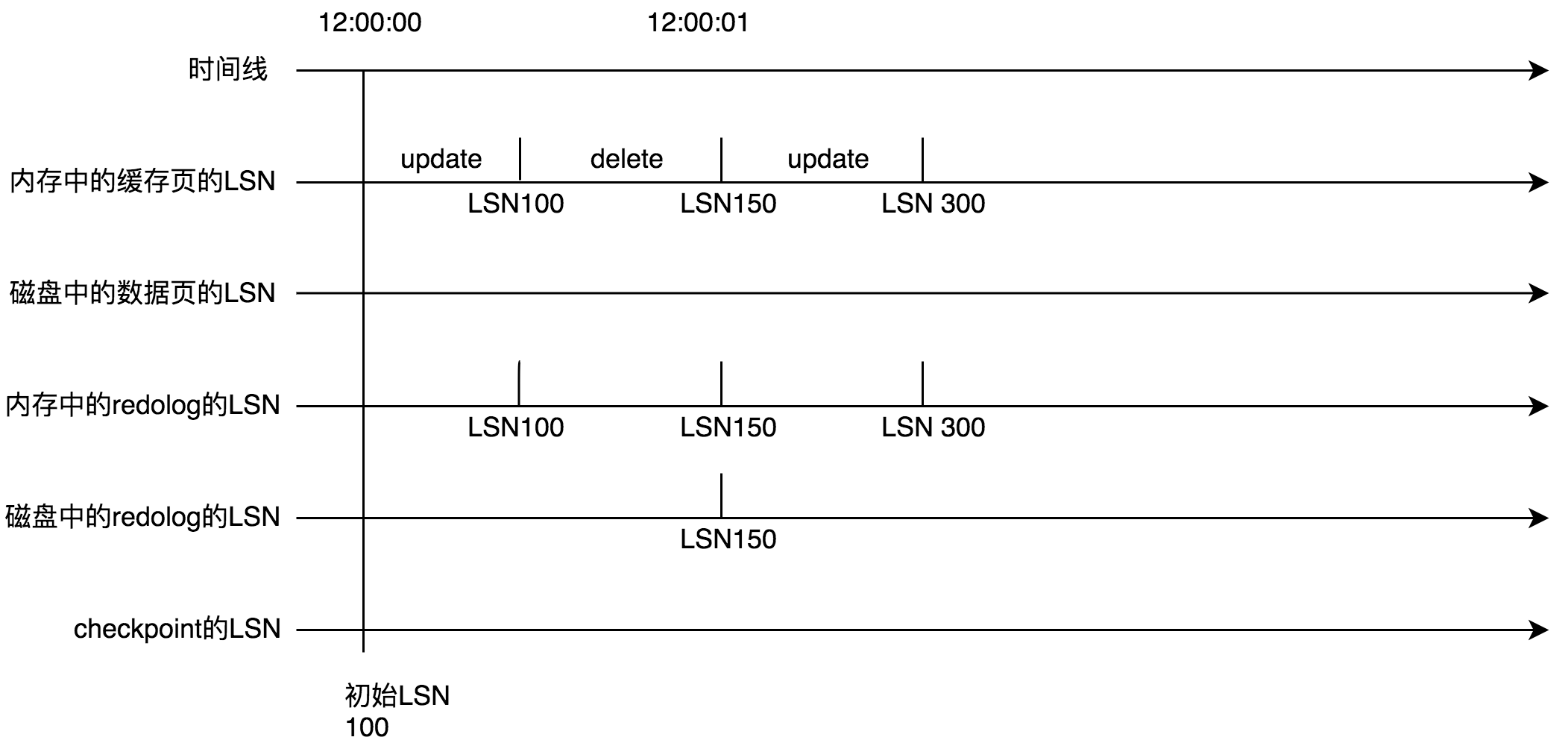
接着你的事物中又执行了一次delete语句。同理内存中的缓存页和内存中的redo log的LSN被更新成了300。
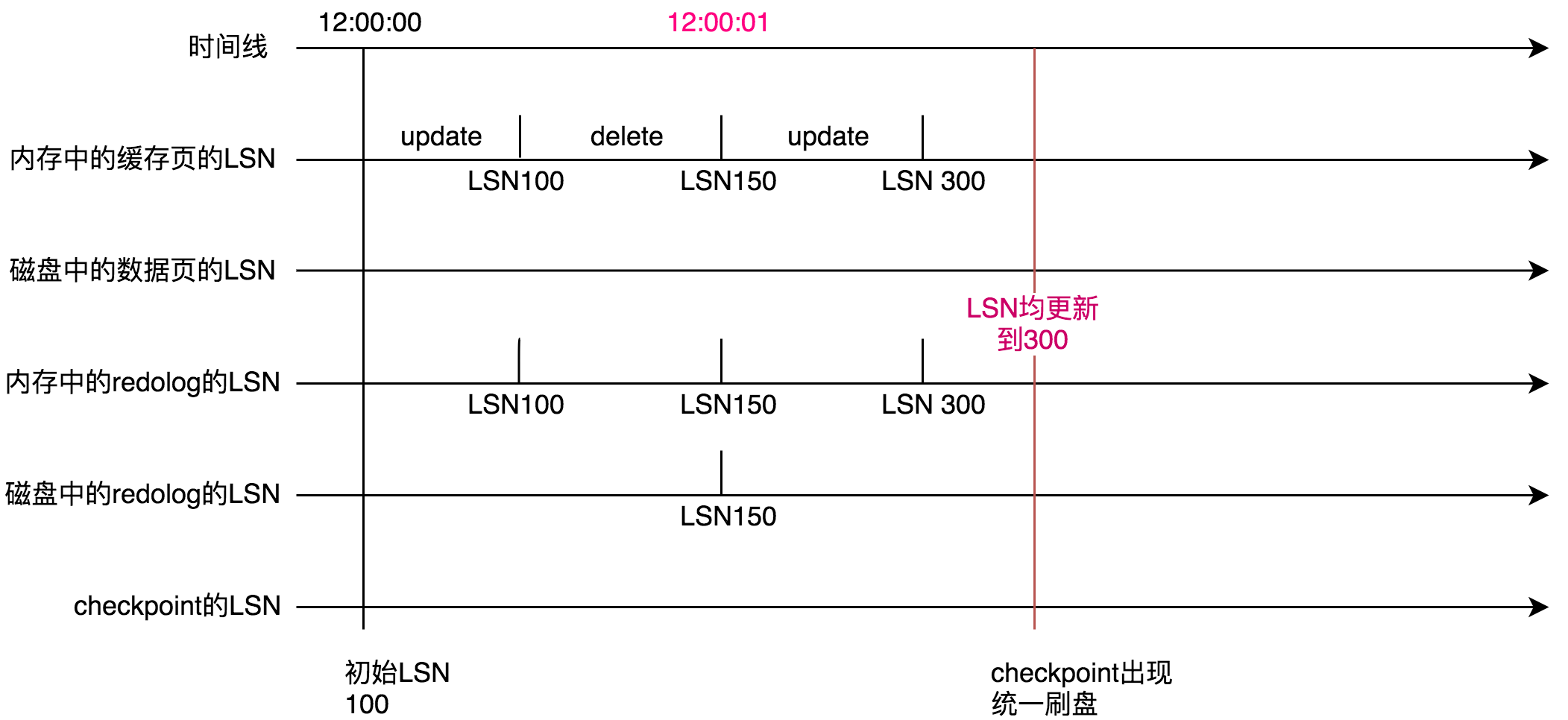
终于checkpoint机制触发了!checkpoint机制的触发意味着要将内存中所有脏数据落盘。因此内存中的缓存页磁盘成为磁盘上的数据页,也就是说磁盘上的数据页的LSN变成300。同理磁盘上的redo log的LSN变成300。checkpoint的LSN也更新成300。
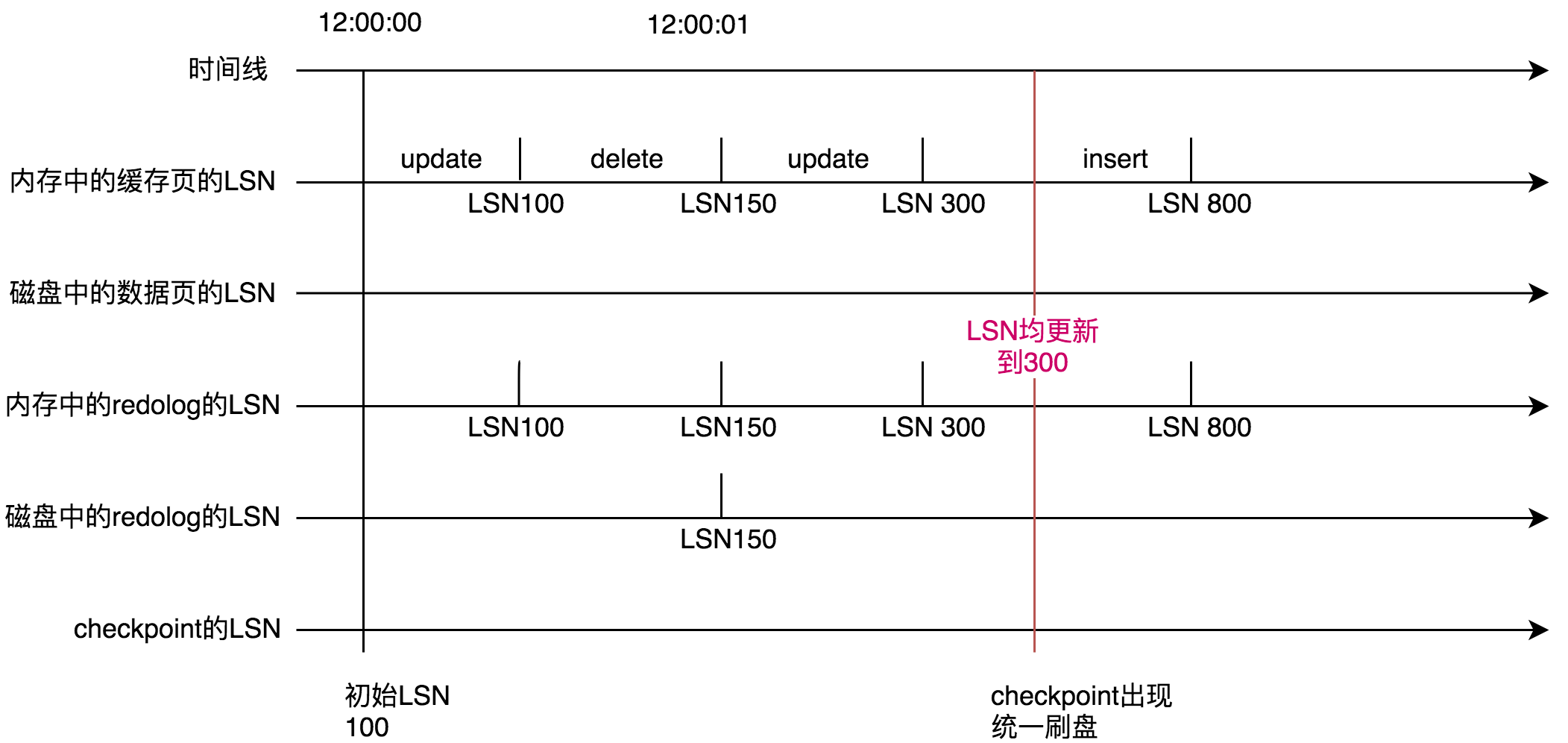
然而你的事物并没有结束,你在12:00:02时刻又insert了一条数据,同上面的原因内存中的缓存页、内存中的redo log 的LSN被更新成800。
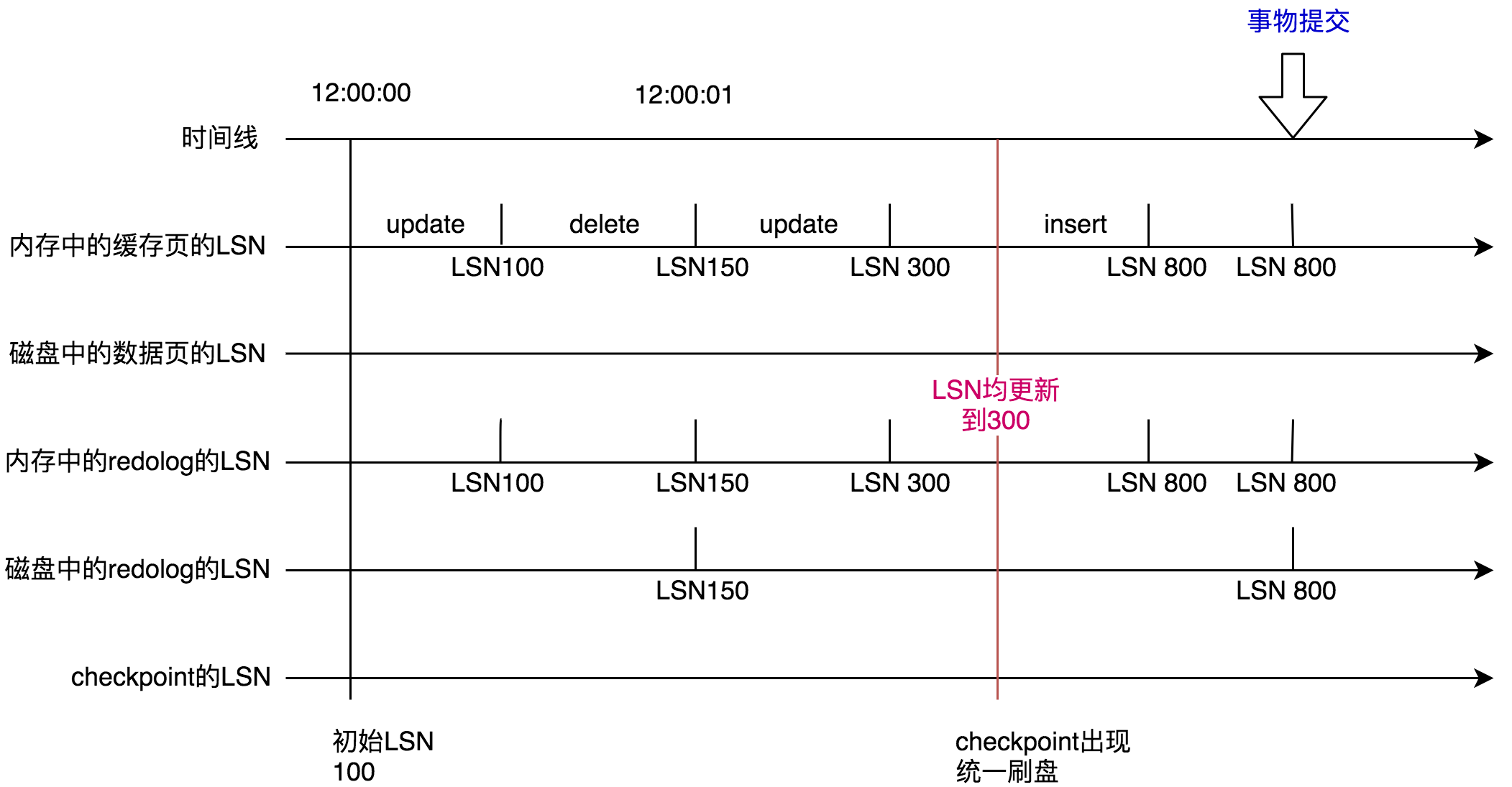
终于你的要提交事物了!默认情况下,根据上一篇文章中跟大家分享的双1配置。事物提交时,redo log会落盘,但是内存中的脏数据并不会落盘。所以磁盘上的redo log LSN被更新成800。也就是说此时除了表空间中的数据页的LSN、checkpoint的LSN其他的LSN均已达到最新的800。
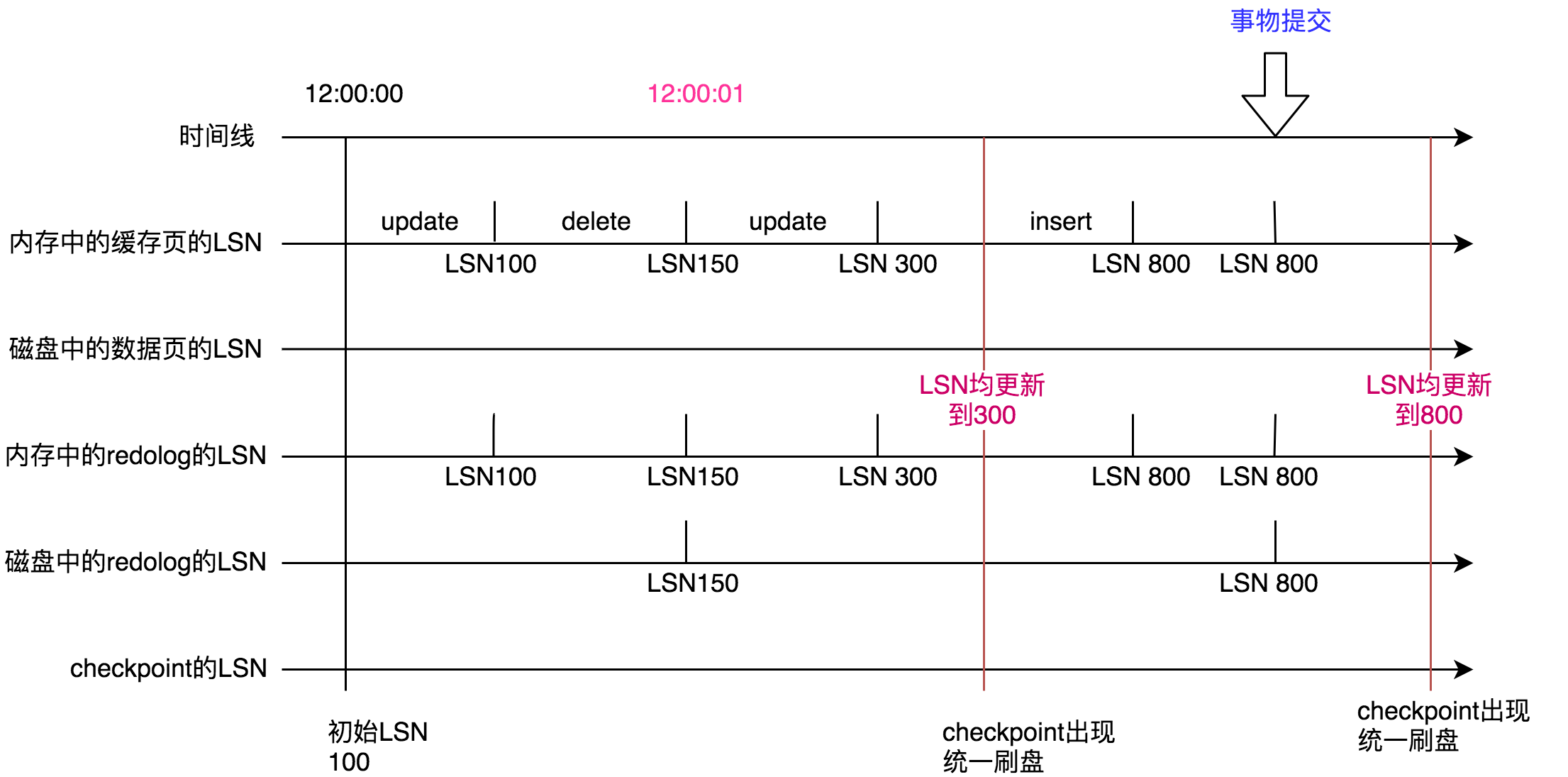
直到最后checkpoint再次出现。这五者LSN重新保持一致。
上述说的什么表空间、数据页、缓存页之前的文章中都说过了。忘记了可以自行翻看哈。
参考:
《MySQL技术内幕》
https://dev.mysql.com/doc/refman/5.7/en/innodb-Checkpoints.html
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_Checkpoint
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_flush
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_lsn
https://blog.csdn.net/gdj0001/article/details/83510447

一起看下MySQL的崩溃恢复到底是怎么回事
标签:额外 序列号 epg target 脏数据 buffer 说明 系统调用 数据段