时间:2021-07-01 10:21:17 帮助过:23人阅读
2000万行的数据表,首先对Address字段做‘%xxx%‘模糊查询
这是估计的查询计划
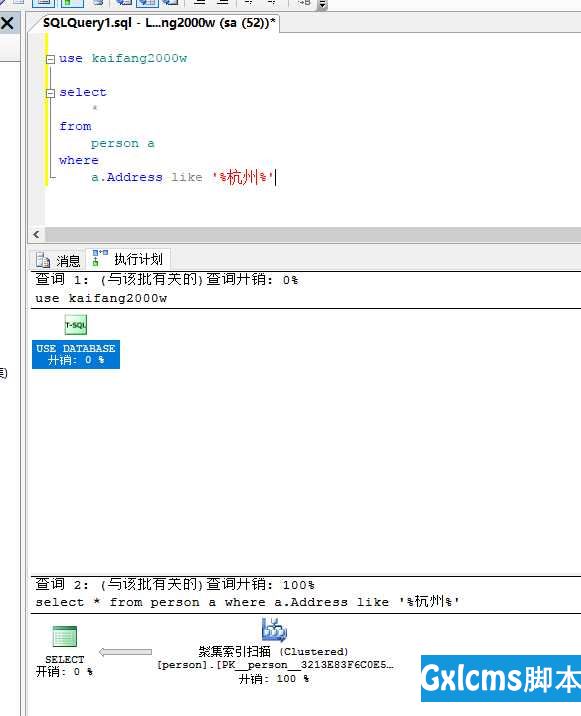
这是估计的实际查询结果,用了37秒才查询完成

还是之前的数据,但是这一次使用‘xxx%‘来做查询,现在还没有做索引
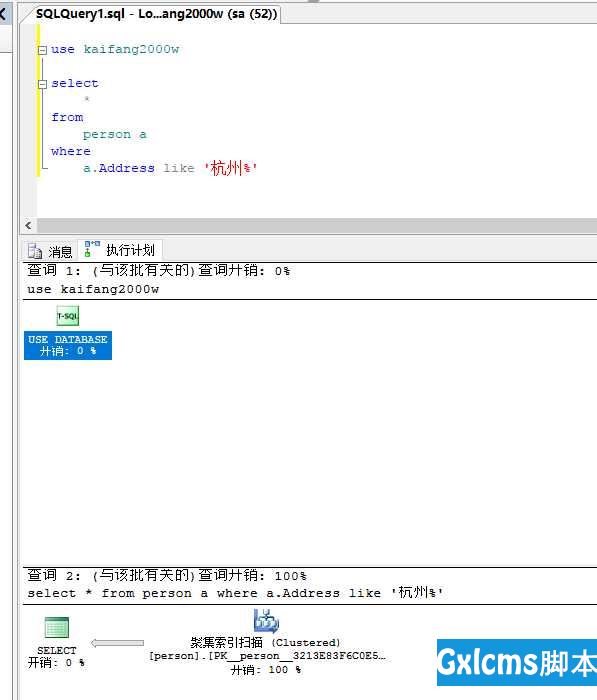
查询速度为10秒,依然是做了全表扫描

接下来的这个不是模糊查询,直接的=,查询多了一个步骤“并行度”
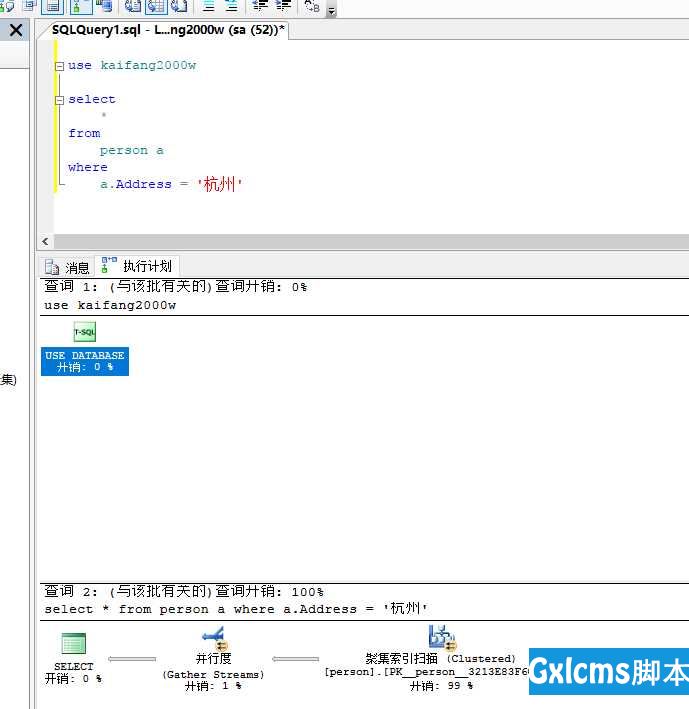
三秒钟完成查询,也是很慢的,应该都是走了全表扫描
现在为Address字段建立一个普通索引
建好普通索引之后尝试进行‘%xxx%‘查找,从查询计划来看,‘%xxx%‘是无法利用到普通索引的
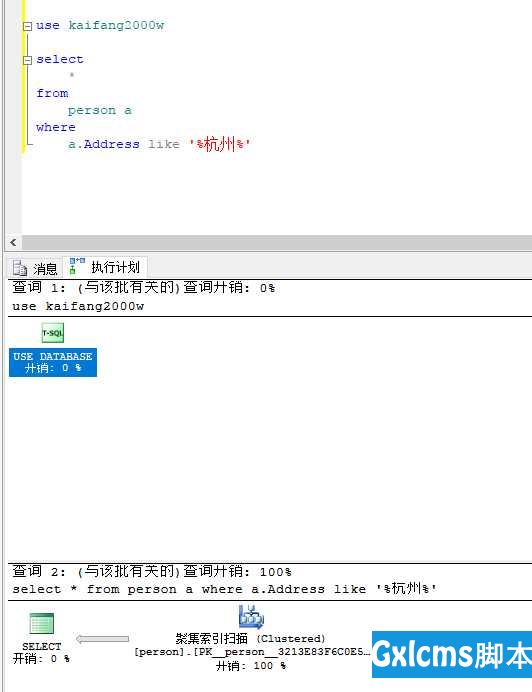
果然,查询耗时和没有建立索引之前一样,基本没变

现在尝试查询‘xxx%‘,根据查询计划可以看到,这种查询可以走刚刚我们建立的普通索引
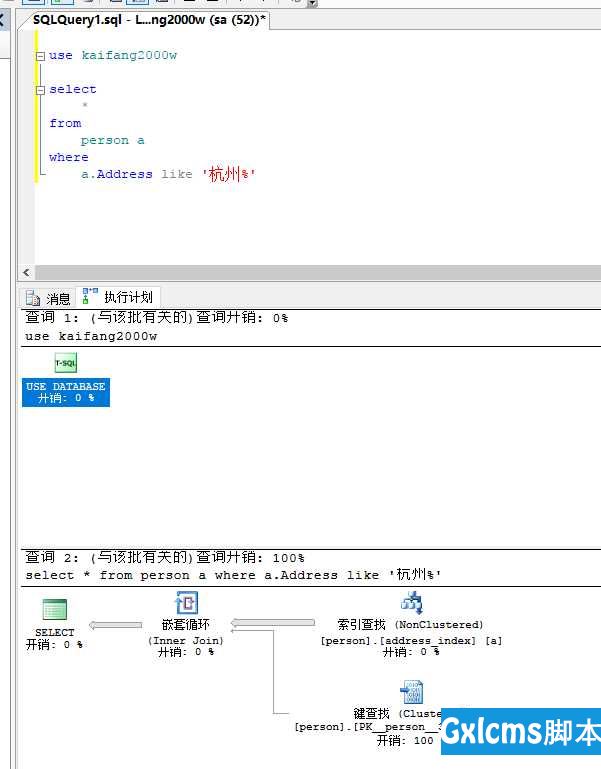
查询结果为4秒,之前没有建立索引的时候查询结果为10秒,缩小了一倍

接着,直接=查找,可以看出利用了索引
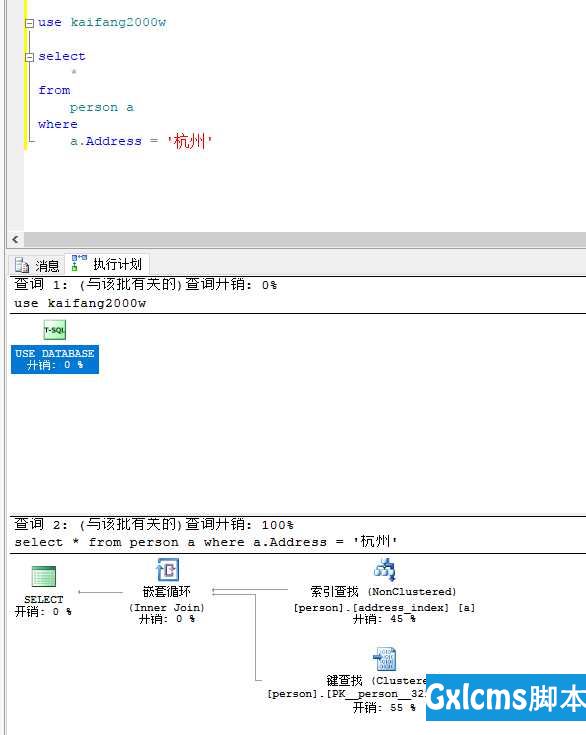
查询耗时0秒,降到了毫秒级别,从这点可以看出,普通的非聚集索引对于直接匹配(=)查询的支持是最好的,然后是like ‘xxxx%‘,而like ‘%xxx%‘不支持

然后我们在Address字段上建立一个全文索引
下面是全文索引的使用语法,以及查询过程
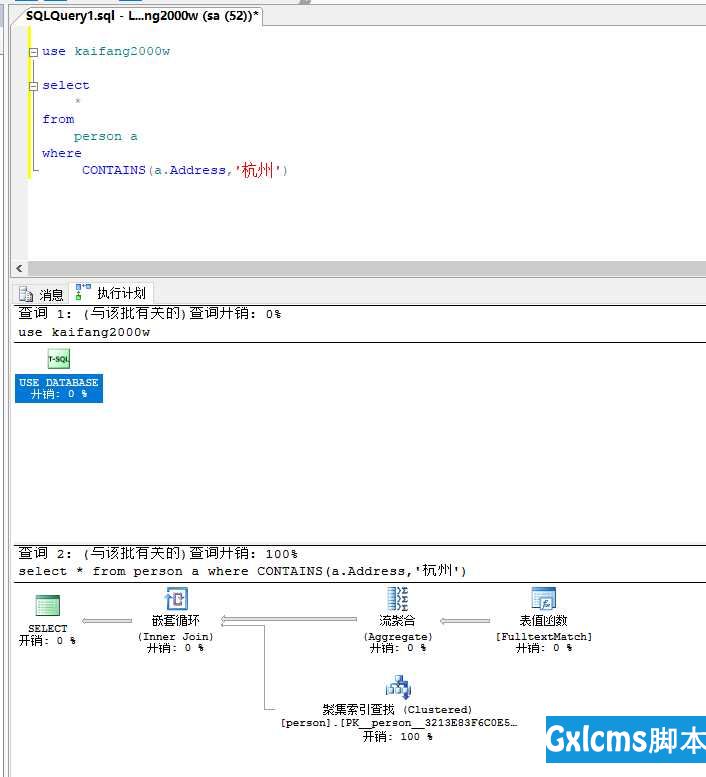
全文索引添加之后,查询时间为2秒,还是有点慢,后来测试了几次,一般是在一秒左右

另外SQLServer2008的全文索引貌似不会立马建立完成,而是需要在后台等待一段时间才能完全建立,在这段时间里面查询返回的结果是不一样的。
如下图,两次查询后一次的结果比前一次多,全文索引正在建立中,最后会有一个稳定的状态。
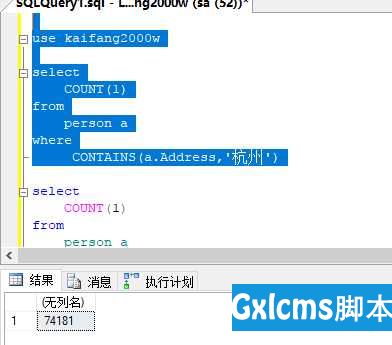
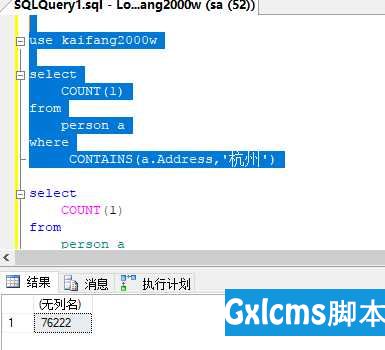
sqlserver的like '%xxx%'优化,全文索引
标签:img ima 利用 估计 有一个 address src 索引 png