时间:2021-07-01 10:21:17 帮助过:14人阅读
Put方法在内部最终会调用Write方法,只是在上层为调用者提供了两个不同的选择。
Get 和 Put 是 LevelDB 为上层提供的用于读写的接口,如果我们能够对读写的过程有一个非常清晰的认知,那么理解 LevelDB 的实现就不是那么困难了。
在这一节中,我们将先通过对读写操作的分析了解整个工程中的一些实现,并在遇到问题和新的概念时进行解释,我们会在这个过程中一步一步介绍 LevelDB 中一些重要模块的实现以达到掌握它的原理的目标。
首先来看 Get 和 Put 两者中的写方法:
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
...
}
正如上面所介绍的,DB::Put 方法将传入的参数封装成了一个 WritaBatch,然后仍然会执行 DBImpl::Write 方法向数据库中写入数据;写入方法 DBImpl::Write 其实是一个是非常复杂的过程,包含了很多对上下文状态的判断,我们先来看一个写操作的整体逻辑:

从总体上看,LevelDB 在对数据库执行写操作时,会有三个步骤:
MakeRoomForWrite 方法为即将进行的写入提供足够的空间;
MemTable 对象;AddRecord 方法向日志中追加一条写操作的记录;InsertInto 直接插入 memtable 中,完成整个写操作的流程;在这里,我们并不会提供 LevelDB 对于 Put 方法实现的全部代码,只会展示一份精简后的代码,帮助我们大致了解一下整个写操作的流程:
Status DBImpl::Write(const WriteOptions& options, WriteBatch* my_batch) {
Writer w(&mutex_);
w.batch = my_batch;
MakeRoomForWrite(my_batch == NULL);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
WriteBatch* updates = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
log_->AddRecord(WriteBatchInternal::Contents(updates));
WriteBatchInternal::InsertInto(updates, mem_);
versions_->SetLastSequence(last_sequence);
return Status::OK();
}
在写操作的实现代码 DBImpl::Put 中,写操作的准备过程 MakeRoomForWrite 是我们需要注意的一个方法:
Status DBImpl::MakeRoomForWrite(bool force) {
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = NULL;
env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.Release_Store(imm_);
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
MaybeScheduleCompaction();
return Status::OK();
}
当 LevelDB 中的 memtable 已经被数据填满导致内存已经快不够用的时候,我们会开始对 memtable 中的数据进行冻结并创建一个新的 MemTable 对象。
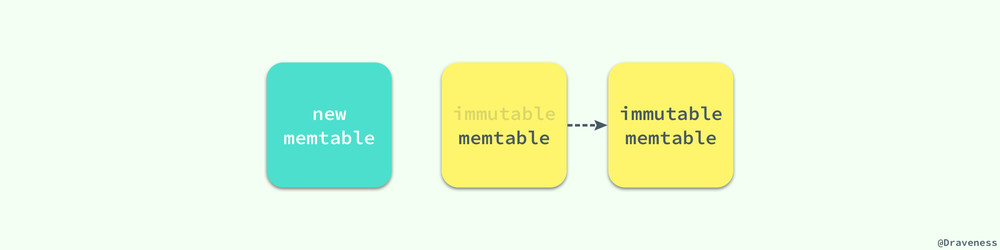
你可以看到,与 Bigtable 中论文不同的是,LevelDB 中引入了一个不可变的 memtable 结构 imm,它的结构与 memtable 完全相同,只是其中的所有数据都是不可变的。
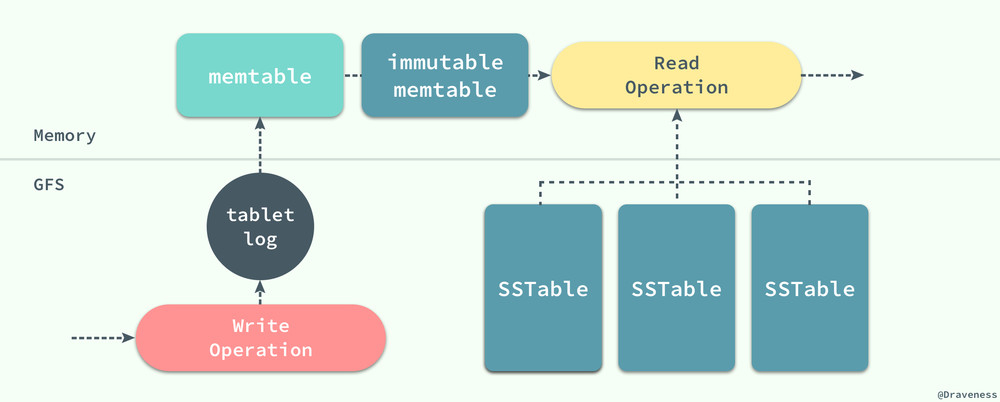
在切换到新的 memtable 之后,还可能会执行 MaybeScheduleCompaction 来触发一次 Minor Compaction 将 imm 中数据固化成数据库中的 SSTable;imm 的引入能够解决由于 memtable 中数据过大导致压缩时不可写入数据的问题。
引入 imm 后,如果 memtable 中的数据过多,我们可以直接将 memtable 指针赋值给 imm,然后创建一个新的 MemTable 实例,这样就可以继续接受外界的写操作,不再需要等待 Minor Compaction 的结束了。
作为一个持久存储的 KV 数据库,LevelDB 一定要有日志模块以支持错误发生时恢复数据,我们想要深入了解 LevelDB 的实现,那么日志的格式是一定绕不开的问题;这里并不打算展示用于追加日志的方法 AddRecord 的实现,因为方法中只是实现了对表头和字符串的拼接。
日志在 LevelDB 是以块的形式存储的,每一个块的长度都是 32KB,固定的块长度也就决定了日志可能存放在块中的任意位置,LevelDB 中通过引入一位 RecordType 来表示当前记录在块中的位置:
enum RecordType {
// Zero is reserved for preallocated files
kZeroType = 0,
kFullType = 1,
// For fragments
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
};
日志记录的类型存储在该条记录的头部,其中还存储了 4 字节日志的 CRC 校验、记录的长度等信息:
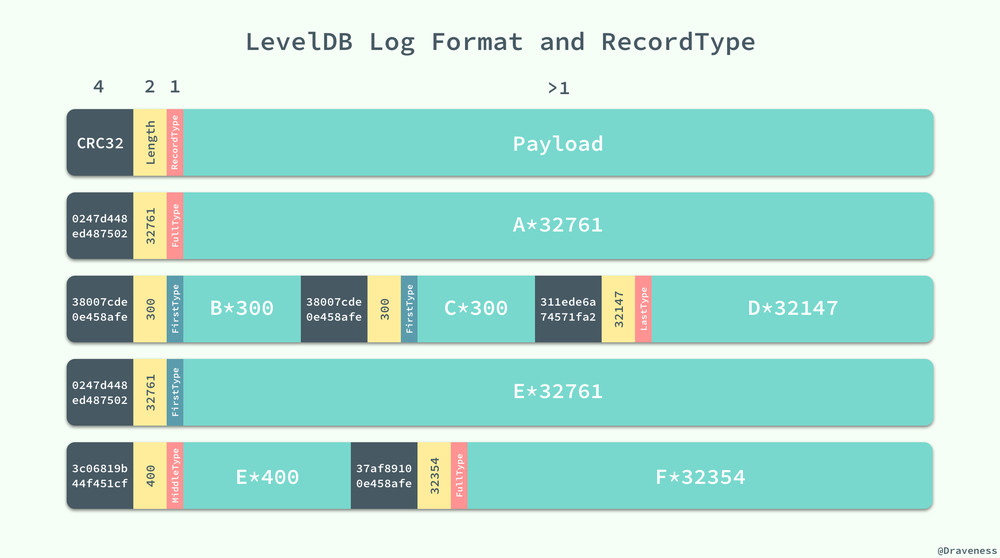
上图中一共包含 4 个块,其中存储着 6 条日志记录,我们可以通过 RecordType 对每一条日志记录或者日志记录的一部分进行标记,并在日志需要使用时通过该信息重新构造出这条日志记录。
virtual Status Sync() {
Status s = SyncDirIfManifest();
if (fflush_unlocked(file_) != 0 ||
fdatasync(fileno(file_)) != 0) {
s = Status::IOError(filename_, strerror(errno));
}
return s;
}
因为向日志中写新记录都是顺序写的,所以它写入的速度非常快,当在内存中写入完成时,也会直接将缓冲区的这部分的内容 fflush 到磁盘上,实现对记录的持久化,用于之后的错误恢复等操作。
当一条数据的记录写入日志时,这条记录仍然无法被查询,只有当该数据写入 memtable 后才可以被查询,而这也是这一节将要介绍的内容,无论是数据的插入还是数据的删除都会向 memtable 中添加一条记录。
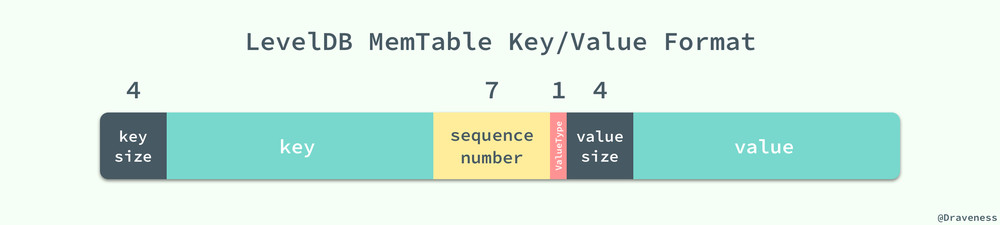
添加和删除的记录的区别就是它们使用了不用的 ValueType 标记,插入的数据会将其设置为 kTypeValue,删除的操作会标记为 kTypeDeletion;但是它们实际上都向 memtable 中插入了一条数据。
virtual void Put(const Slice& key, const Slice& value) {
mem_->Add(sequence_, kTypeValue, key, value);
sequence_++;
}
virtual void Delete(const Slice& key) {
mem_->Add(sequence_, kTypeDeletion, key, Slice());
sequence_++;
}
我们可以看到它们都调用了 memtable 的 Add 方法,向其内部的数据结构 skiplist 以上图展示的格式插入数据,这条数据中既包含了该记录的键值、序列号以及这条记录的种类,这些字段会在拼接后存入 skiplist;既然我们并没有在 memtable 中对数据进行删除,那么我们是如何保证每次取到的数据都是最新的呢?首先,在 skiplist 中,我们使用了自己定义的一个 comparator:
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const {
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == 0) {
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8);
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8);
if (anum > bnum) {
r = -1;
} else if (anum < bnum) {
r = +1;
}
}
return r;
}
比较的两个 key 中的数据可能包含的内容都不完全相同,有的会包含键值、序列号等全部信息,但是例如从
Get方法调用过来的 key 中可能就只包含键的长度、键值和序列号了,但是这并不影响这里对数据的提取,因为我们只从每个 key 的头部提取信息,所以无论是完整的 key/value 还是单独的 key,我们都不会取到 key 之外的任何数据。
该方法分别从两个不同的 key 中取出键和序列号,然后对它们进行比较;比较的过程就是使用 InternalKeyComparator 比较器,它通过 user_key 和 sequence_number 进行排序,其中 user_key 按照递增的顺序排序、sequence_number 按照递减的顺序排序,因为随着数据的插入序列号是不断递增的,所以我们可以保证先取到的都是最新的数据或者删除信息。

在序列号的帮助下,我们并不需要对历史数据进行删除,同时也能加快写操作的速度,提升 LevelDB 的写性能。
从 LevelDB 中读取数据其实并不复杂,memtable 和 imm 更像是两级缓存,它们在内存中提供了更快的访问速度,如果能直接从内存中的这两处直接获取到响应的值,那么它们一定是最新的数据。
LevelDB 总会将新的键值对写在最前面,并在数据压缩时删除历史数据。
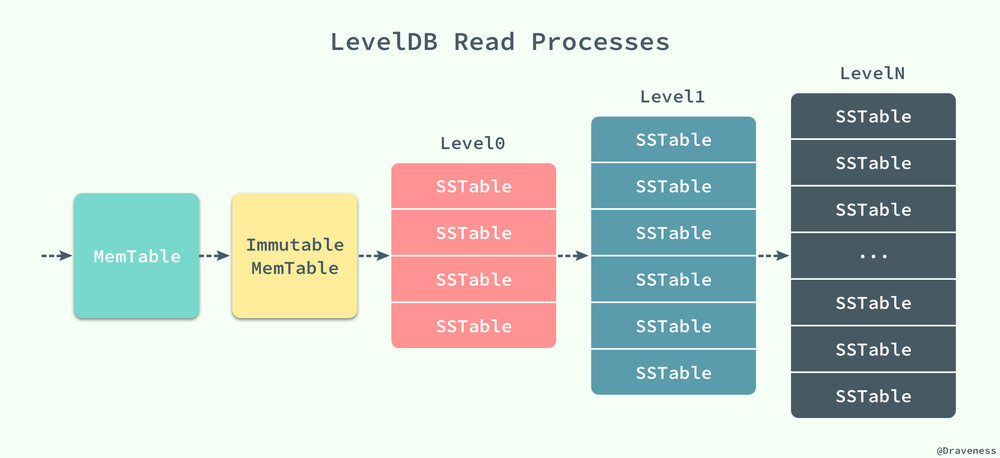
数据的读取是按照 MemTable、Immutable MemTable 以及不同层级的 SSTable 的顺序进行的,前两者都是在内存中,后面不同层级的 SSTable 都是以 *.ldb 文件的形式持久存储在磁盘上,而正是因为有着不同层级的 SSTable,所以我们的数据库的名字叫做 LevelDB。
精简后的读操作方法的实现代码是这样的,方法的脉络非常清晰,作者相信这里也不需要过多的解释:
Status DBImpl::Get(const ReadOptions& options, const Slice& key, std::string* value) {
LookupKey lkey(key, versions_->LastSequence());
if (mem_->Get(lkey, value, NULL)) {
// Done
} else if (imm_ != NULL && imm_->Get(lkey, value, NULL)) {
// Done
} else {
versions_->current()->Get(options, lkey, value, NULL);
}
MaybeScheduleCompaction();
return Status::OK();
}
当 LevelDB 在 memtable 和 imm 中查询到结果时,如果查询到了数据并不一定表示当前的值一定存在,它仍然需要判断 ValueType 来确定当前记录是否被删除。
当 LevelDB 在内存中没有找到对应的数据时,它才会到磁盘中多个层级的 SSTable 中进行查找,这个过程就稍微有一点复杂了,LevelDB 会在多个层级中逐级进行查找,并且不会跳过其中的任何层级;在查找的过程就涉及到一个非常重要的数据结构 FileMetaData:

FileMetaData 中包含了整个文件的全部信息,其中包括键的最大值和最小值、允许查找的次数、文件被引用的次数、文件的大小以及文件号,因为所有的 SSTable 都是以固定的形式存储在同一目录下的,所以我们可以通过文件号轻松查找到对应的文件。

查找的顺序就是从低到高了,LevelDB 首先会在 Level0 中查找对应的键。但是,与其他层级不同,Level0 中多个 SSTable 的键的范围有重合部分的,在查找对应值的过程中,会依次查找 Level0 中固定的 4 个 SSTable。
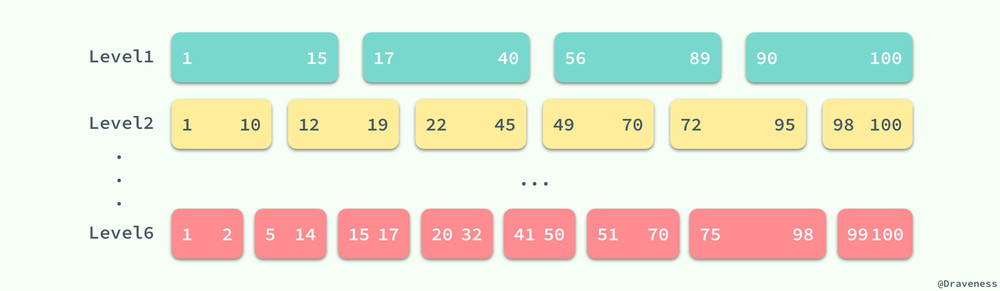
但是当涉及到更高层级的 SSTable 时,因为同一层级的 SSTable 都是没有重叠部分的,所以我们在查找时可以利用已知的 SSTable 中的极值信息 smallest/largest 快速查找到对应的 SSTable,再判断当前的 SSTable 是否包含查询的 key,如果不存在,就继续查找下一个层级直到最后的一个层级 kNumLevels(默认为 7 级)或者查询到了对应的值。
既然 LevelDB 中的数据是通过多个层级的 SSTable 组织的,那么它是如何对不同层级中的 SSTable 进行合并和压缩的呢;与 Bigtable 论文中描述的两种 Compaction 几乎完全相同,LevelDB 对这两种压缩的方式都进行了实现。
无论是读操作还是写操作,在执行的过程中都可能调用 MaybeScheduleCompaction 来尝试对数据库中的 SSTable 进行合并,当合并的条件满足时,最终都会执行 BackgroundCompaction 方法在后台完成这个步骤。
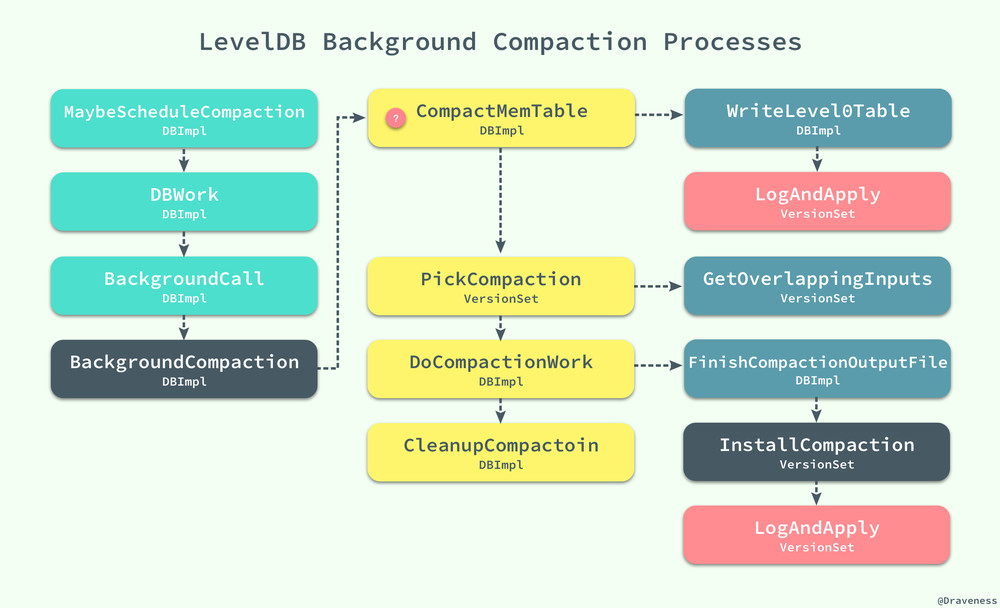
这种合并分为两种情况,一种是 Minor Compaction,即内存中的数据超过了 memtable 大小的最大限制,改 memtable 被冻结为不可变的 imm,然后执行方法 CompactMemTable() 对内存表进行压缩。
void DBImpl::CompactMemTable() {
VersionEdit edit;
Version* base = versions_->current();
WriteLevel0Table(imm_, &edit, base);
versions_->LogAndApply(&edit, &mutex_);
DeleteObsoleteFiles();
}
CompactMemTable 会执行 WriteLevel0Table 将当前的 imm 转换成一个 Level0 的 SSTable 文件,同时由于 Level0 层级的文件变多,可能会继续触发一个新的 Major Compaction,在这里我们就需要在这里选择需要压缩的合适的层级:
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit, Version* base) {
FileMetaData meta;
meta.number = versions_->NewFileNumber();
Iterator* iter = mem->NewIterator();
BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
const Slice min_user_key = meta.smallest.user_key();
const Slice max_user_key = meta.largest.user_key();
int level = base->PickLevelForMemTableOutput(min_user_key, max_user_key);
edit->AddFile(level, meta.number, meta.file_size, meta.smallest, meta.largest);
return Status::OK();
}
所有对当前 SSTable 数据的修改由一个统一的 VersionEdit 对象记录和管理,我们会在后面介绍这个对象的作用和实现,如果成功写入了就会返回这个文件的元数据 FileMetaData,最后调用 VersionSet 的方法 LogAndApply 将文件中的全部变化如实记录下来,最后做一些数据的清理工作。
当然如果是 Major Compaction 就稍微有一些复杂了,不过整理后的 BackgroundCompaction 方法的逻辑非常清晰:
void DBImpl::BackgroundCompaction() {
if (imm_ != NULL) {
CompactMemTable();
return;
}
Compaction* c = versions_->PickCompaction();
CompactionState* compact = new CompactionState(c);
DoCompactionWork(compact);
CleanupCompaction(compact);
DeleteObsoleteFiles();
}
我们从当前的 VersionSet 中找到需要压缩的文件信息,将它们打包存入一个 Compaction 对象,该对象需要选择两个层级的 SSTable,低层级的表很好选择,只需要选择大小超过限制的或者查询次数太多的 SSTable;当我们选择了低层级的一个 SSTable 后,就在更高的层级选择与该 SSTable 有重叠键的 SSTable 就可以了,通过 FileMetaData 中数据的帮助我们可以很快找到待压缩的全部数据。
查询次数太多的意思就是,当客户端调用多次
Get方法时,如果这次Get方法在某个层级的 SSTable 中找到了对应的键,那么就算做上一层级中包含该键的 SSTable 的一次查找,也就是这次查找由于不同层级键的覆盖范围造成了更多的耗时,每个 SSTable 在创建之后的allowed_seeks都为 100 次,当allowed_seeks < 0时就会触发该文件的与更高层级和合并,以减少以后查询的查找次数。
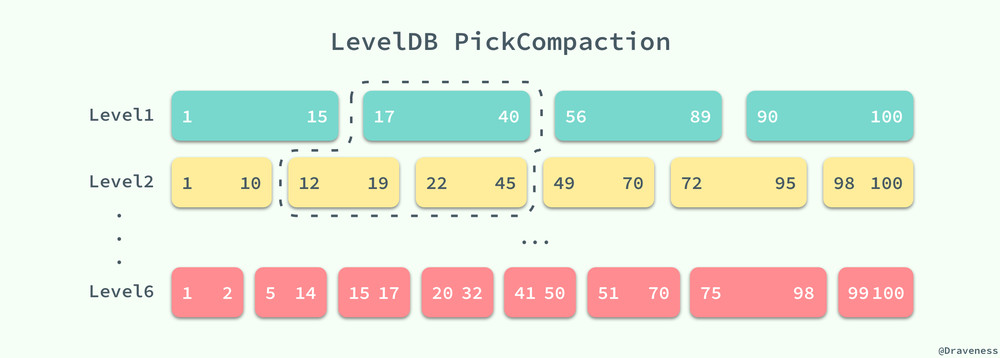
LevelDB 中的 DoCompactionWork 方法会对所有传入的 SSTable 中的键值使用归并排序进行合并,最后会在高高层级(图中为 Level2)中生成一个新的 SSTable。
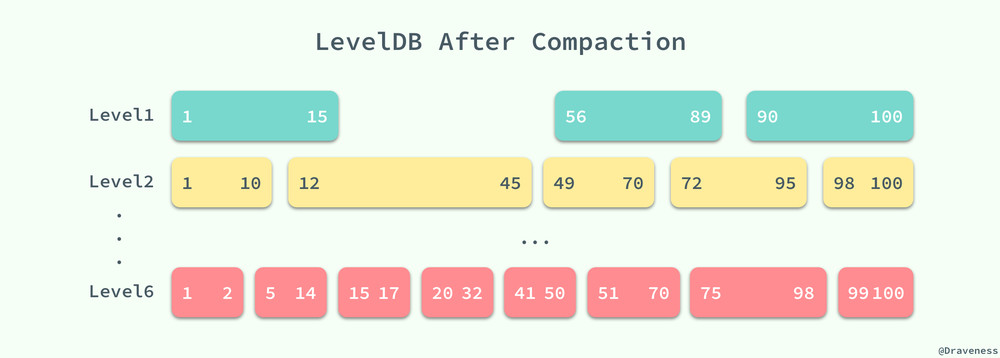
这样下一次查询 17~40 之间的值时就可以减少一次对 SSTable 中数据的二分查找以及读取文件的时间,提升读写的性能。
LevelDB 中的所有状态其实都是被一个 VersionSet 结构所存储的,一个 VersionSet 包含一组 Version 结构体,所有的 Version 包括历史版本都是通过双向链表连接起来的,但是只有一个版本是当前版本。
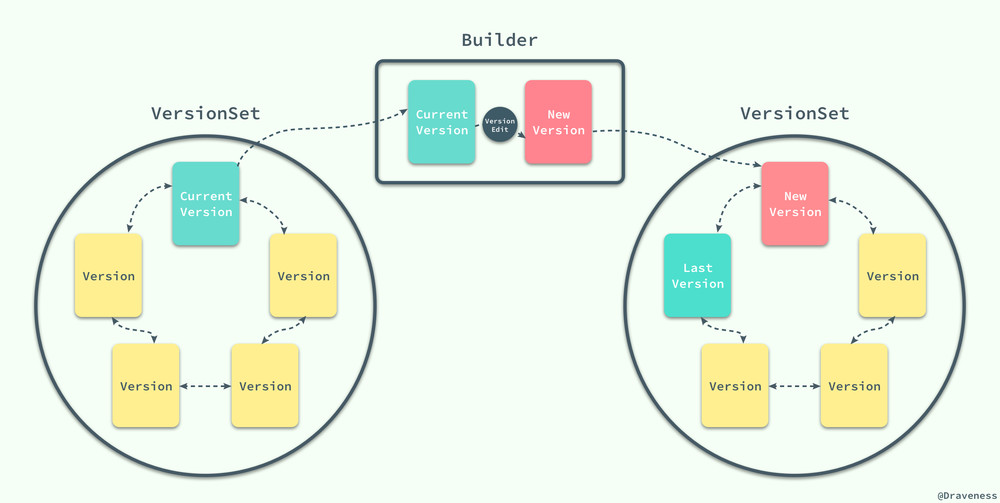
当 LevelDB 中的 SSTable 发生变动时,它会生成一个 VersionEdit 结构,最终执行 LogAndApply 方法:
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
Version* v = new Version(this);
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
std::string new_manifest_file;
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
env_->NewWritableFile(new_manifest_file, &descriptor_file_);
std::string record;
edit->EncodeTo(&record);
descriptor_log_->AddRecord(record);
descriptor_file_->Sync();
SetCurrentFile(env_, dbname_, manifest_file_number_);
AppendVersion(v);
return Status::OK();
}
该方法的主要工作是使用当前版本和 VersionEdit 创建一个新的版本对象,然后将 Version 的变更追加到 MANIFEST 日志中,并且改变数据库中全局当前版本信息。
MANIFEST 文件中记录了 LevelDB 中所有层级中的表、每一个 SSTable 的 Key 范围和其他重要的元数据,它以日志的格式存储,所有对文件的增删操作都会追加到这个日志中。
SSTable 中其实存储的不只是数据,其中还保存了一些元数据、索引等信息,用于加速读写操作的速度,虽然在 Bigtable 的论文中并没有给出 SSTable 的数据格式,不过在 LevelDB 的实现中,我们可以发现 SSTable 是以这种格式存储数据的:
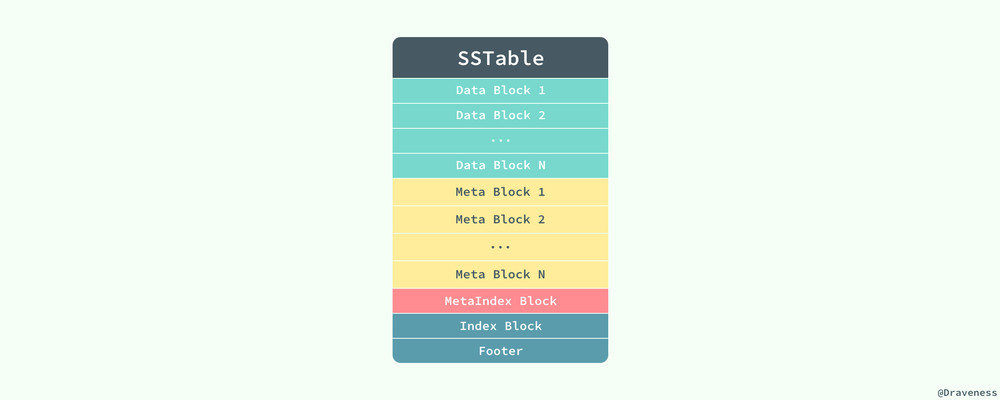
当 LevelDB 读取 SSTable 存在的 ldb 文件时,会先读取文件中的 Footer 信息。
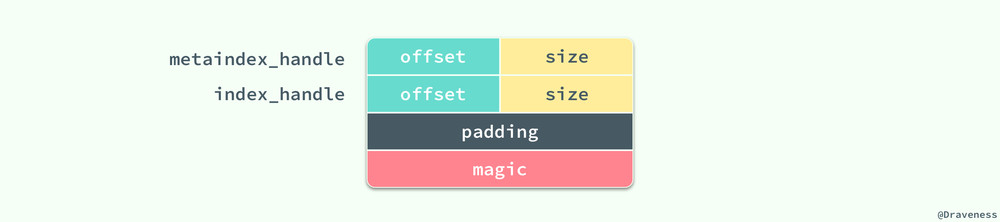
整个 Footer 在文件中占用 48 个字节,我们能在其中拿到 MetaIndex 块和 Index 块的位置,再通过其中的索引继而找到对应值存在的位置。
TableBuilder::Rep 结构体中就包含了一个文件需要创建的全部信息,包括数据块、索引块等等:
struct TableBuilder::Rep {
WritableFile* file;
uint64_t offset;
BlockBuilder data_block;
BlockBuilder index_block;
std::string last_key;
int64_t num_entries;
bool closed;
FilterBlockBuilder* filter_block;
...
}
到这里,我们就完成了对整个数据读取过程的解析了;对于读操作,我们可以理解为 LevelDB 在它内部的『多级缓存』中依次查找是否存在对应的键,如果存在就会直接返回,唯一与缓存不同可能就是,在数据『命中』后,它并不会把数据移动到更近的地方,而是会把数据移到更远的地方来减少下一次的访问时间,虽然这么听起来却是不可思议,不过仔细想一下确实是这样。
在这篇文章中,我们通过对 LevelDB 源代码中读写操作的分析,了解了整个框架的绝大部分实现细节,包括 LevelDB 中存储数据的格式、多级 SSTable、如何进行合并以及管理版本等信息,不过由于篇幅所限,对于其中的一些问题并没有展开详细地进行介绍和分析,例如错误恢复以及缓存等问题;但是对 LevelDB 源代码的阅读,加深了我们对 Bigtable 论文中描述的分布式 KV 存储数据库的理解。
LevelDB 的源代码非常易于阅读,也是学习 C++ 语言非常优秀的资源,如果对文章的内容有疑问,可以在博客下面留言。