时间:2021-07-01 10:21:17 帮助过:10人阅读
1 def SQLite_Test():
2 # =========== 连接数据库 ============
3 # 1. 连接本地数据库
4 connectA = sqlite3.connect("example.db")
5 # 2. 连接内存数据库,在内存中创建临时数据库
6 connectB = sqlite3.connect(":memory:")
7
8 # =========== 创建游标对象 ============
9 cursorA = connectA.cursor()
10 cursorB = connectB.cursor()
11
12 # =========== 创建表 ============
13 cursorA.execute("CREATE TABLE class(id real, name text, age real, sex text)")
14 cursorB.execute("CREATE TABLE family(relation text, job text, age real)")
15
16 # =========== 插入数据 ============
17 cursorA.execute("INSERT INTO class VALUES(1,‘Jock‘,8,‘M‘)")
18 cursorA.execute("INSERT INTO class VALUES(2,‘Mike‘,10,‘M‘)")
19 # 使用 ? 占位符
20 cursorA.execute("INSERT INTO class VALUES(?,?,?,?)", (3,‘Sarah‘,9,‘F‘))
21
22 families = [
23 [‘Dad‘, ‘CEO‘, 35],
24 [‘Mom‘, ‘singer‘, 33],
25 [‘Brother‘, ‘student‘, 8]
26 ]
27 cursorB.executemany("INSERT INTO family VALUES(?,?,?)",families)
28
29 # =========== 查找数据 ============
30 # 使用 命名变量 占位符
31 cursorA.execute("SELECT * FROM class WHERE sex=:SEX", {"SEX":‘M‘})
32 print("TABLE class: >>>select Male\n", cursorA.fetchone())
33 cursorA.close()
34
35 cursorB.execute("SELECT * FROM family ORDER BY relation")
36 print("TABLE family:\n", cursorB.fetchall())
37 cursorB.close()
38
39 # =========== 断开连接 ============
40 connectA.close()
41 connectB.close()
42
43 SQLite_Test()

运行结果:
TABLE class: >>>select Male
(1.0, ‘Jock‘, 8.0, ‘M‘)
TABLE family:
[(‘Brother‘, ‘student‘, 8.0), (‘Dad‘, ‘CEO‘, 35.0), (‘Mom‘, ‘singer‘, 33.0)]
使用目前学的sqlite3数据库知识,对一些数据进行增删查改的操作。此处选择来自下面网站的数据
url = http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
先将数据从网站上爬取下来,存储为csv文件,然后再保存到数据库中,接着进行数据的操作。对于如何存储为csv文件,请查看 >>> 《此处的最后一个小主题》
对于本次小练习的介绍:
目的:对已爬取的数据进行数据库管理和简单操作
步骤: 创建数据库文件 >>> 创建表 >>> 保存数据到数据库 >>> 对数据进行简单操作
方法:我采用的方法是:
① 编写一个函数( get_data(fileName) ):读取csv文件中的数据,主要完成对数据的格式转换,以便适合保存到数据库中
② 编写一个函数类( class SQL_method ):对数据库进行简单操作,主要完成数据库的创建和数据的增删查改
| 方法 | 说明 |
| __init__(self, dbName, tabelName, data, columns, COLUMNS, Read_All=True) | 对参数进行初始化,参数含义分别为:数据库名称、表格名称、数据、表格首行(用于创建表)、表格首行(用于格式输出)、输出所有数据(插入数据后) |
| creatTable(self) | 创建数据库文件、创建表格 |
| destroyTable(self) | 删除表格 |
| insertDatas(self) | 向数据库的表格中插入多条数据 |
| getAllData(self) | 以列表形式返回数据库表格中的所有数据 |
| searchData(self, condition, IfPrint=True) | 查找特定数据, 参数的含义分别为:查找条件、是否输出(查找的数据) |
| deleteData(self, condition) | 在数据库的表格中删除特定数据, 参数为删除条件 |
| printData(self, data) | 输出数据, 参数为需要输出的数据 |
| run(self) | 运行创建数据库和表格的函数,同时支持输出所有数据(依靠Read_All) |
③ 尝试其他操作 ( 以下的所有操作均在 main 函数中实现 ):
a. 在数据库中查找某一项记录
b. 对数据按照某种排序输出
c. 对数据进行增加权值操作,实现重新排序 【权值详情】
d. 删除数据库中的某些记录
e. 删除数据库中的表
好了,有了前进的方向,那我们杨帆 ----- 起航 >>>
1 # -*- coding: utf-8 -*-
2 ‘‘‘
3 使用 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" 的数据进行SQLite3数据库的练习使用
4 @author: bpf
5 ‘‘‘
6
7 import sqlite3
8 from pandas import DataFrame
9 import re
10
11 class SQL_method:
12 ‘‘‘
13 function: 可以实现对数据库的基本操作
14 ‘‘‘
15 def __init__(self, dbName, tableName, data, columns, COLUMNS, Read_All=True):
16 ‘‘‘
17 function: 初始化参数
18 dbName: 数据库文件名
19 tableName: 数据库中表的名称
20 data: 从csv文件中读取且经过处理的数据
21 columns: 用于创建数据库,为表的第一行
22 COLUMNS: 用于数据的格式化输出,为输出的表头
23 Read_All: 创建表之后是否读取出所有数据
24 ‘‘‘
25 self.dbName = dbName
26 self.tableName = tableName
27 self.data = data
28 self.columns = columns
29 self.COLUMNS = COLUMNS
30 self.Read_All = Read_All
31
32 def creatTable(self):
33 ‘‘‘
34 function: 创建数据库文件及相关的表
35 ‘‘‘
36 # 连接数据库
37 connect = sqlite3.connect(self.dbName)
38 # 创建表
39 connect.execute("CREATE TABLE {}({})".format(self.tableName, self.columns))
40 # 提交事务
41 connect.commit()
42 # 断开连接
43 connect.close()
44
45 def destroyTable(self):
46 ‘‘‘
47 function: 删除数据库文件中的表
48 ‘‘‘
49 # 连接数据库
50 connect = sqlite3.connect(self.dbName)
51 # 删除表
52 connect.execute("DROP TABLE {}".format(self.tableName))
53 # 提交事务
54 connect.commit()
55 # 断开连接
56 connect.close()
57
58 def insertDataS(self):
59 ‘‘‘
60 function: 向数据库文件中的表插入多条数据
61 ‘‘‘
62 # 连接数据库
63 connect = sqlite3.connect(self.dbName)
64 # 插入多条数据
65 connect.executemany("INSERT INTO {} VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)".format(self.tableName), self.data)
66 #for i in range(len(self.data)):
67 # connect.execute("INSERT INTO university VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)", data[i])
68 # 提交事务
69 connect.commit()
70 # 断开连接
71 connect.close()
72
73 def getAllData(self):
74 ‘‘‘
75 function: 得到数据库文件中的所有数据
76 ‘‘‘
77 # 连接数据库
78 connect = sqlite3.connect(self.dbName)
79 # 创建游标对象
80 cursor = connect.cursor()
81 # 读取数据
82 cursor.execute("SELECT * FROM {}".format(self.tableName))
83 dataList = cursor.fetchall()
84 # 断开连接
85 connect.close()
86 return dataList
87
88 def searchData(self, conditions, IfPrint=True):
89 ‘‘‘
90 function: 查找特定的数据
91 ‘‘‘
92 # 连接数据库
93 connect = sqlite3.connect(self.dbName)
94 # 创建游标
95 cursor = connect.cursor()
96 # 查找数据
97 cursor.execute("SELECT * FROM {} WHERE {}".format(self.tableName, conditions))
98 data = cursor.fetchall()
99 # 关闭游标
100 cursor.close()
101 # 断开数据库连接
102 connect.close()
103 if IfPrint:
104 self.printData(data)
105 return data
106
107 def deleteData(self, conditions):
108 ‘‘‘
109 function: 删除数据库中的数据
110 ‘‘‘
111 # 连接数据库
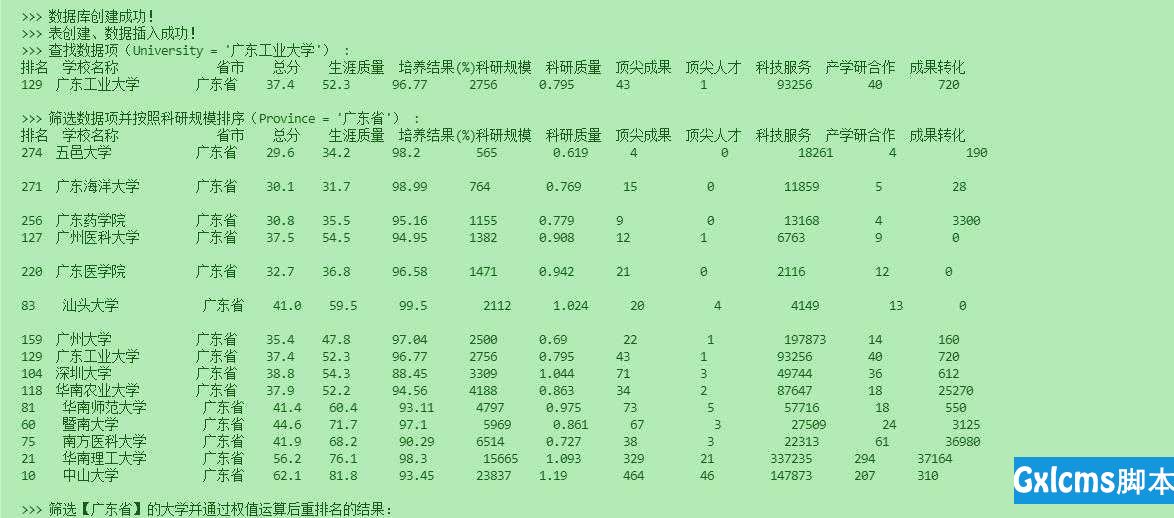
112 connect = sqlite3.connect(self.dbName)
113 # 插入多条数据
114 connect.execute("DELETE FROM {} WHERE {}".format(self.tableName, conditions))
115 # 提交事务
116 connect.commit()
117 # 断开连接
118 connect.close()
119
120 def printData(self, data):
121 print("{1:{0}^3}{2:{0}<11}{3:{0}<4}{4:{0}<4}{5:{0}<5}{6:{0}<5}{7:{0}^5}{8:{0}^5}{9:{0}^5}{10:{0}^5}{11:{0}^5}{12:{0}^6}{13:{0}^5}".format(chr(12288), *self.COLUMNS))
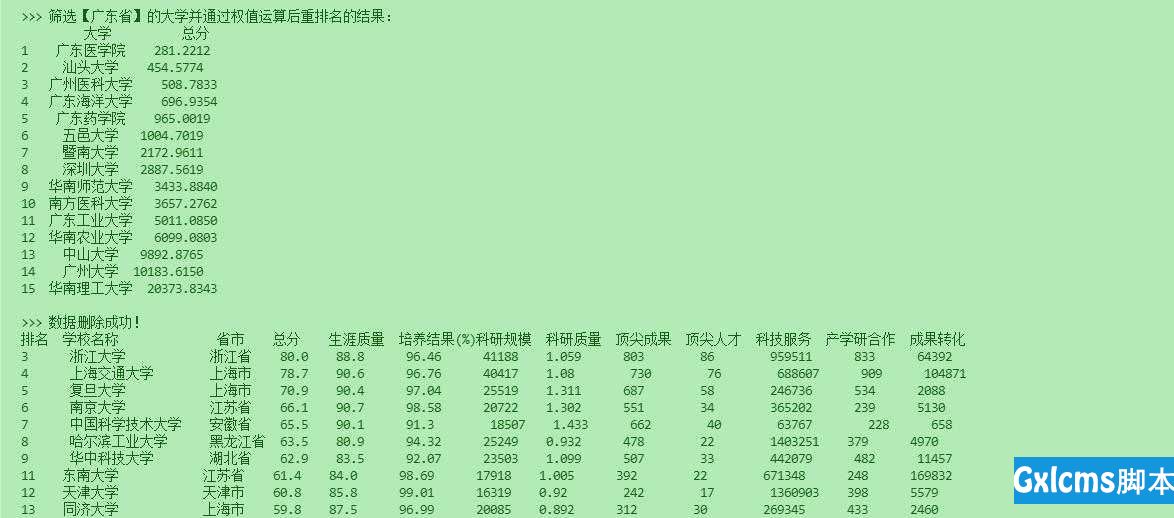
122 for i in range(len(data)):
123 print("{1:{0}<4.0f}{2:{0}<10}{3:{0}<5}{4:{0}<6}{5:{0}<7}{6:{0}<8}{7:{0}<7.0f}{8:{0}<8}{9:{0}<7.0f}{10:{0}<6.0f}{11:{0}<9.0f}{12:{0}<6.0f}{13:{0}<6.0f}".format(chr(12288), *data[i]))
124
125 def run(self):
126 try:
127 # 创建数据库文件
128 self.creatTable()
129 print(">>> 数据库创建成功!")
130 # 保存数据到数据库
131 self.insertDataS()
132 print(">>> 表创建、数据插入成功!")
133 except:
134 print(">>> 数据库已创建!")
135 # 读取所有数据
136 if self.Read_All:
137 self.printData(self.getAllData())
138
139 def get_data(fileName):
140 ‘‘‘
141 function: 读取获得大学排名的数据 并 将结果返回
142 ‘‘‘
143 data = []
144 # 打开文件
145 f = open(fileName, ‘r‘, encoding=‘utf-8‘)
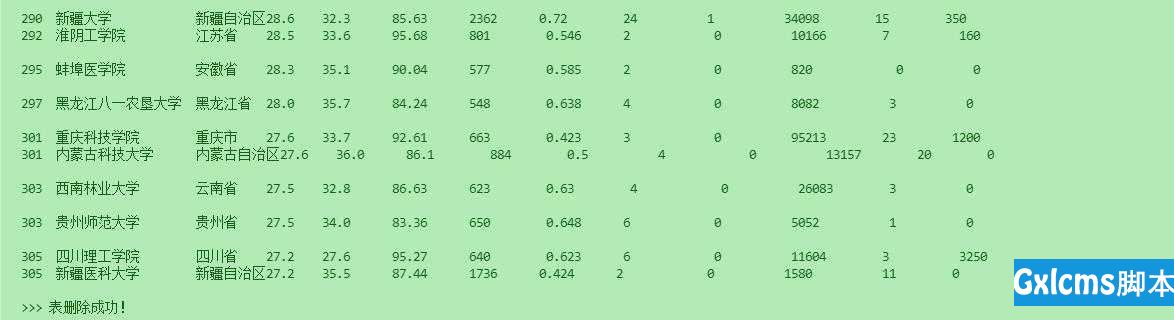
146 # 按行读取文件
147 for line in f.readlines():
148 # 替换掉其中的换行符和百分号 替换百分号是为了方便之后的排序和运算
149 line = line.replace(‘\n‘, ‘‘)
150 line = line.replace(‘%‘,‘‘)
151 # 将字符串按照 ‘,‘ 分割为列表
152 line = line.split(‘,‘)
153
154 for i in range(len(line)):
155 # 使用 异常处理 避开 出现中文无法转换 的错误
156 try:
157 # 将空值填充为 0
158 if line[i] == ‘‘:
159 line[i] = ‘0‘
160 # 将数字转换为数值
161 line[i] = eval(line[i])
162 except:
163 continue
164 data.append(tuple(line))
165 # EN_columns、CH_columns 分别为 用于数据库创建、数据的格式化输出
166 EN_columns = "Rank real, University text, Province text, Grade real, SourseQuality real, TrainingResult real, ResearchScale real, 167 ReserchQuality real, TopResult real, TopTalent real, TechnologyService real, Cooperation real, TransformationResults real"
168 CH_columns = ["排名", "学校名称", "省市", "总分", "生涯质量", "培养结果(%)", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"]
169 return data[1:], EN_columns, CH_columns
170
171 if __name__ == "__main__":
172 # =================== 设置和得到基本数据 ===================
173 fileName = "D:\\University_Rank.csv"
174 data, EN_columns, CH_columns = get_data(fileName)
175 dbName = "university.db"
176 tableName = "university"
177
178 # ================= 创建一个SQL_method对象 ==================
179 SQL = SQL_method(dbName, tableName, data, EN_columns, CH_columns, False)
180
181 # =================== 创建数据库并保存数据 ===================
182 SQL.run()
183
184 # =================== 在数据库中查找数据项 ===================
185 # 查找记录并输出结果
186 print(">>> 查找数据项(University = ‘广东工业大学‘) :")
187 SQL.searchData("University = ‘广东工业大学‘", True)
188
189 # ================= 在数据库中筛选数据项并排序 ==================
190 # 将选取广东省的数据 并 对科研规模大小排序
191 print("\n>>> 筛选数据项并按照科研规模排序(Province = ‘广东省‘) :")
192 SQL.searchData("Province = ‘广东省‘ ORDER BY ResearchScale", True)
193
194 # =============== 对数据库中的数据进行重新排序操作 ================
195 # 定义权值
196 Weight = [0.3, 0.15, 0.1, 0.1, 0.1, 0.1, 0.05, 0.05, 0.05]
197 value, sum = [], 0
198 # 获取 Province = ‘广东省‘ 的所有数据
199 sample = SQL.searchData("Province = ‘广东省‘", False)
200 # 按照权值求出各个大学的总得分
201 for i in range(len(sample)):
202 for j in range(len(Weight)):
203 sum += sample[i][4+j] * Weight[j]
204 value.append(sum)
205 sum = 0
206 # 将结果通过 pandas 的 DataFrame 方法组成一个二维序列
207 university = [university[1] for university in sample]
208 uv, tmp = [], []
209 for i in range(len(university)):
210 tmp.append(university[i])
211 tmp.append(value[i])
212 uv.append(tmp)
213 tmp = []
214 df = DataFrame(uv, columns=list(("大学", "总分")))
215 df = df.sort_values(‘总分‘)
216 df.index = [i for i in range(1, len(uv)+1)]
217 # 输出结果
218 print("\n>>> 筛选【广东省】的大学并通过权值运算后重排名的结果:\n", df)
219
220 # ===================== 在数据库中删除数据项 =====================
221 SQL.deleteData("Province = ‘北京市‘")
222 SQL.deleteData("Province = ‘广东省‘")
223 SQL.deleteData("Province = ‘山东省‘")
224 SQL.deleteData("Province = ‘山西省‘")
225 SQL.deleteData("Province = ‘江西省‘")
226 SQL.deleteData("Province = ‘河南省‘")
227 print("\n>>> 数据删除成功!")
228 SQL.printData(SQL.getAllData())
229
230 # ====================== 在数据库中删除表 ========================
231 SQL.destroyTable()
232 print(">>> 表删除成功!
数据库实践
标签:sea lda tuple out dbn DBName fetch 方法 author