时间:2021-07-01 10:21:17 帮助过:36人阅读
本篇文章主要讲述了用scrapy实现新浪微博爬虫,具有一定的参考价值,感兴趣的朋友可以了解一下 ,看完不妨自己去试试哦!
最近因为做毕设的原因,需要采集一批数据。本着自己动手的原则,从新浪微博上采集到近百位大家耳熟能详的明星14-18年的微博内容。看看大佬们平常都在微博上都有哪些动态吧~
1.首先项目采用scrapy编写,省时省力谁用谁知道。
采集的网站为weibo.com,是微博的网页端。稍稍麻烦了一点,但相对于移动段和wap站点来说内容稍微更全一点。
2.采集之前我们先来看下微博都给我们设置了哪些障碍。
由于微博对于没登录的用户默认都是302跳转到登录界面,所以采集微博钱必须得让微博认为,本次采集偷了个懒,直接是先手动登录然后保存cookie到scrapy上,请求的时候带上cookie去访问,因为采集量并不是很大,估计也就10w条左右。这里需要对刚入scrapy的小伙伴需要提醒一下,scrapy的cookie是类似与json的形式,不像平常在requests上直接粘贴就可以用,需要转换一下格式。
大概就是像这样,所以需要把登录后的cookie粘贴出来用代码转换一下,代码如下:
class transCookie:
def __init__(self, cookie):
self.cookie = cookie
def stringToDict(self):
itemDict = {}
items = self.cookie.split(';')
for item in items:
key = item.split('=')[0].replace(' ', '')
value = item.split('=')[1]
itemDict[key] = value
return itemDict
if __name__ == "__main__":
cookie = "你的cookie"
trans = transCookie(cookie)
print(trans.stringToDict())应该来说一个cookie差不多够用,我这我保存的是三个cookie,多个cookie简单的办法是把多个cookie直接放在一个数组里面,每次请求的时候用random函数随机挑一个出来,当然这只是针对采一批数据就撤的情况,大规模必须维护一个账号池。请求的时候带上ua,和cookie。如下:
微博是以oid区分每个用户的,我们以吴彦祖微博为例,在微博搜索界面搜索吴彦祖,进入主页右键查看网页源代码我们可以看到:
此处的oid即是每个用户的唯一标识。对应用户的主页地址即为https://weibo.com + oid,
有了地址,我们直接进入微博界面进行采集即可,拼凑出url地址,例如:
https://weibo.com/wuyanzu?is_all=1&stat_date=201712#feedtop
这是吴彦祖2017年12月份的微博,我们不难发现,只需改变stat_date后面的数字即为对应微博地址。对于某些微博量比较多的用户,月份的微博可能还涉及到js再加载一次,当然,我们高冷的男神吴彦祖先生肯定是不会发那么多的,我们再找一个微博量比较大的自媒体,例如:
可以看到,余下的微博是需要通过js异步加载来呈现给用户的。打开浏览器开发者模式,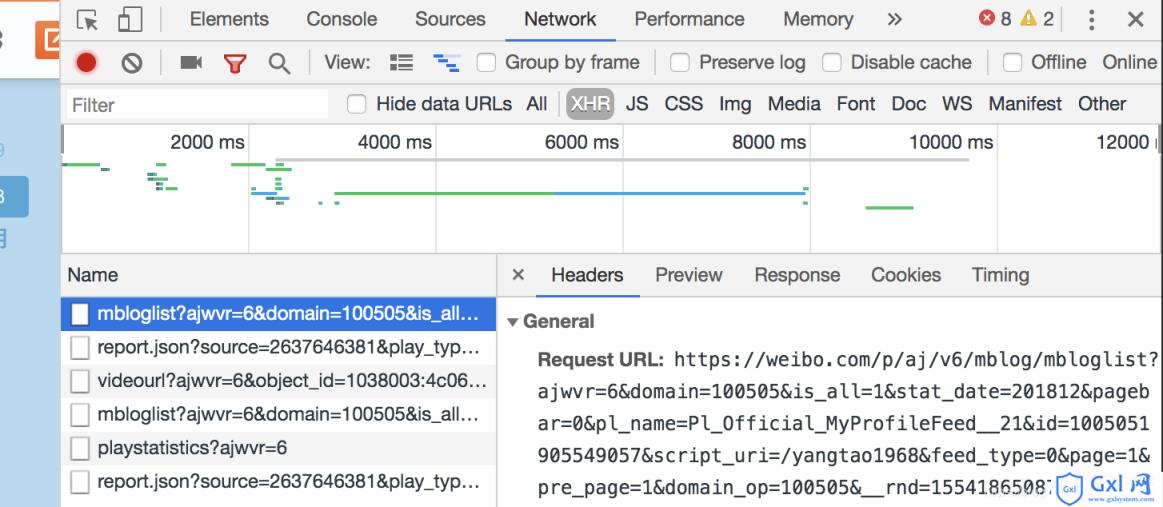
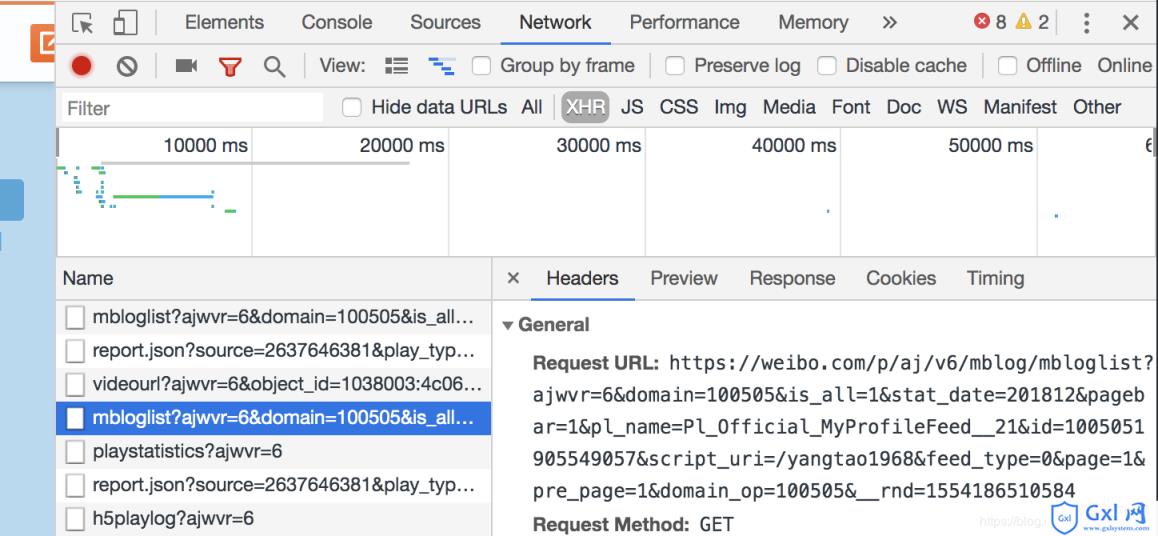
对比两次js加载的页面,我们不难发现,Request_URL差别的地方仅仅是在pagebar和_rnd两个参数上,第一个代表页数,第二个是时间的加密(测试不带上也无妨),因此我们仅仅需要构建页数即可。有些微博量巨多的可能还需要翻页,道理相同。
class SpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
nickname = scrapy.Field()
follow = scrapy.Field()
fan = scrapy.Field()
weibo_count = scrapy.Field()
authentication = scrapy.Field()
address = scrapy.Field()
graduated = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
oid = scrapy.Field()设置需要爬取的字段nickname昵称,follow关注,fan粉丝,weibo_count微博数量,authentication认证信息,address地址,graduated毕业院校,有些微博不显示的默认设置为空,以及oid和博文内容及发布时间。
这里说一下内容的解析,还是吴彦祖微博,如果我们还是像之前一样直接用scrapy的解析规则去用xpath或者css选择器解析会发现明明结构找的正确却匹配不出数据,这就是微博坑的地方,点开源代码。我们发现:
微博的主题内容全是用script包裹起来的!!!这个问题当初也是困扰了博主很久,反复换着法子用css和xpath解析始终不出数据。
解决办法:正则匹配(无奈但有效)
至此,就可以愉快的进行采集了,附上运行截图:
输入导入mongodb:
相关教程:Python视频教程
以上就是scrapy实现新浪微博爬虫的详细内容,更多请关注Gxl网其它相关文章!