时间:2021-07-01 10:21:17 帮助过:72人阅读
核心类
1.Cookie
该类实现了Netscape and RFC 2965 cookies定义的cookie标准,基本可以理解为某一条cookie数据。
部分代码如下,很多属性是不是很眼熟?
self.domain_initial_dot = domain_initial_dot
self.path = path
self.path_specified = path_specified
self.secure = secure
self.expires = expires
self.discard = discard
self.comment = comment
self.comment_url = comment_url
self.rfc2109 = rfc2109
2.CookiePolicy
该类的主要功能是收发cookie,即确保正确的cookie发往对应的域名,反之一样。
3.DefaultCookiePolicy
该类实现了CookiePolicy的接口。
4.CookieJar
CookieJar是cookie的集合,可以包含有很多Cookie类,是我们的主要操作对象。里面有一系列的方法可以支持更加细致的操作!
5.FileCookieJar
该类继承自CookieJar,CookieJar只是在内存中完成自己的生命周期,FileCookieJar的子类能够实现数据持久化,定义了save、load、revert三个接口。
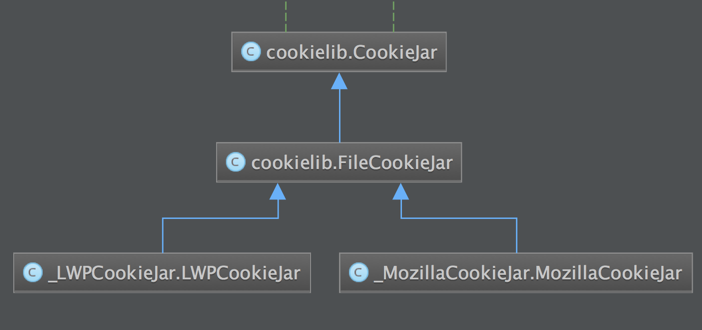
6.MozillaCookieJar & LWPCookieJar
两个实现类,继承关系如下:
实例:登录人人网
在firefox下使用httpFox插件来查到人人网的登录时需要POST的地址是http://www.renren.com/ajaxLogin

而且查看到需要POST的DATA有email和password
python通过cookielib来处理cookie,以下是简单的代码
>>> import urllib
>>> import urllib2,cookielib
>>> login_page = "http://www.renren.com/ajaxLogin"
>>> cj = cookielib.CookieJar()
>>> opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
>>> opener.add_handler = [('User-agent','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)')]
>>> data = urllib.urlencode({"email":'username',"password":'password'})
>>> opener.open(login_page,data)
>
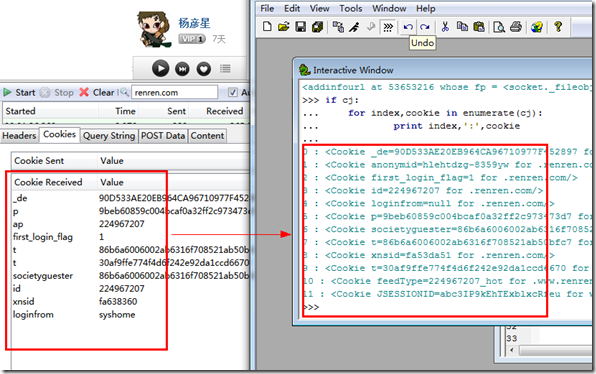
>>> if cj:
... for index,cookie in enumerate(cj):
... print index,':',cookie
...
0 :
可以和firebug或者httpFox中得到的cookie进行对比,值可能不一致,但key基本上是一致的,你每次登录应该都不一致
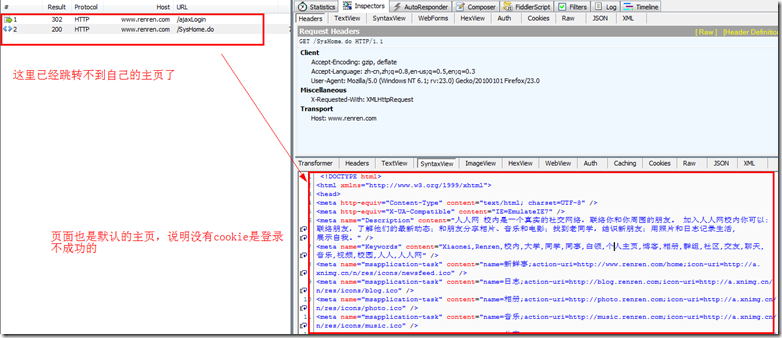
我也尝试过使用fidder模拟发送没有cookie的POST数据,但是没有得到想要的返回值
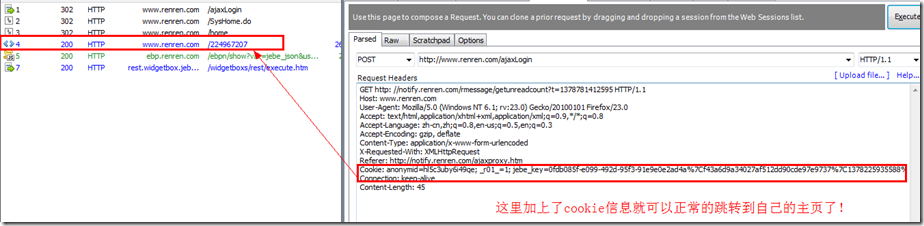
而加上cookie信息以后就可以正常的跳转到自己的主页了
好了,基本上了解了python中使用cookie来发送登录信息,现在我们来写一个小脚本来登录自己人人网。
#encoding=utf-8
import urllib2
import urllib
import cookielib
def renrenBrower(url,user,password):
login_page = "http://www.renren.com/ajaxLogin"
try:
cj = cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)')]
data = urllib.urlencode({"email":user,"password":password})
opener.open(login_page,data)
op=opener.open(url)
data= op.read()
return data
except Exception,e:
print str(e)
print renrenBrower("http://www.renren.com/home","用户名","密码")
这样就可以将自己首页的信息显示出来了,其实在登录完以后,还可以接着写脚本来获取自己想要的信息,如朋友的新鲜事等,这里就不作过多说明了~