时间:2021-07-01 10:21:17 帮助过:109人阅读
 如图所示想得到 820,但是动态产生的。该新闻的url为 陕西眉县发红头文件:官员卖水泥买房纳入考核
如图所示想得到 820,但是动态产生的。该新闻的url为 陕西眉县发红头文件:官员卖水泥买房纳入考核

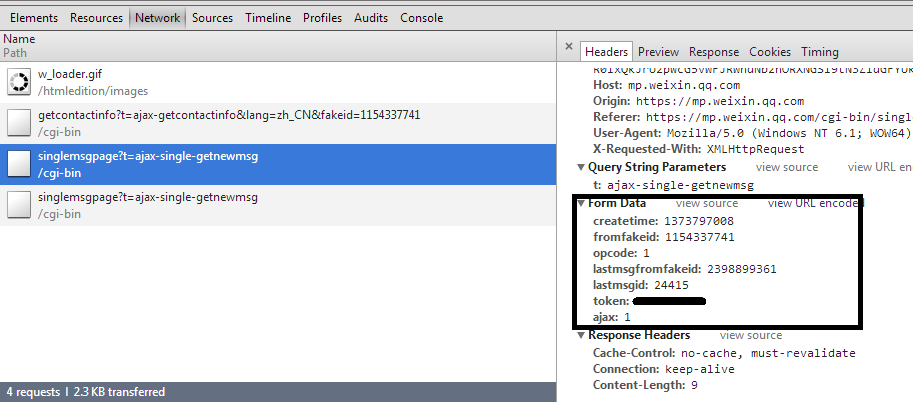 这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。
这是微信公众平台获取聊天信息的action,fromfakeid就是聊天对方的id。import selenium
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://news.sina.com.cn/c/2013-07-11/175827642839.shtml ") # Load page
time.sleep(5) # Let the page load
try:
element = browser.find_element_by_xpath("//span[contains(@class,'f_red')]") # get element on page
print element.text # get element text
except NoSuchElementException:
assert 0, "can't find f_red"
browser.close()
>>> from selenium import webdriver
>>> c = webdriver.Chrome()
>>> c.get('http://news.sina.com.cn/c/2013-07-11/175827642839.shtml')
>>> comment = c.find_element_by_id('media_comment')
>>> count = comment.find_element_by_class_name('f_red')
>>> count.text
u'823'