时间:2021-07-01 10:21:17 帮助过:44人阅读


 关于实现,可以参考我的博客:http://xlzd.me/2016/01/31/python-crawler-09
关于实现,可以参考我的博客:http://xlzd.me/2016/01/31/python-crawler-09



原子镜的学名其实叫做 单向透视玻璃,但是在淘宝上搜 原子镜 这个关键词会好些
单面镜其实是“双面镜”,单面镜前后两面的光学性质根本没有分别,它之所以能产生单面反光的效果,完全是因为镜的两面处于不同光度的环境所造成的。我们先比较普通镜子和单面镜的结构。普通镜子是把银镀在玻璃上制成的。单面镜也一样,可是在镀银时就只会镀“一半”。怎样可以镀“一半”呢?方法倒是有点巧妙:镀上去的银(不是真银,是其他金属)十分薄,使一半的光可以通过,另一半就被反射回去。在实际使用时,犯人会面向镜面,而且身处有强光的房间。因为光线充足,反射的光较多,犯人便会在镜中看见自己的影象。此时证人站在镜的另一边,一个光线很微弱的房间里。虽然证人房间里部分的光线也可以穿过单面反光镜,但由于光度很低,所以犯人便看不到证人,只能看到自己的影像。情形就好像在街灯的强光下,我们不能看见萤火虫一样,因为来自萤火虫的微弱光线被街灯的光所盖过了。因此所谓单面反光的现象,只是视觉上的错觉罢了! (摘自百度百科)
原子镜广泛应用于监狱、公检法机构审讯室、精神病医院、大学科研机构研究室、大型会议室等,可达到里面看不到外面,外面可看到里面的效果。


这种厕所上起来感受应该比较刺激
当然还有应用于酒(tou)店(pai)的,所以在网上也有很多卖小尺寸的原子镜,一般是10x10cm的一块10块钱,我这个是12x14cm的也是10块钱,但是邮费就要20,所以很划不来,据说现在有种单透膜,可以达到同样的效果,没有研究过。
接下来说 LCD屏幕
我使用的是深圳微信公司出的4英寸LCD屏,这个屏幕用起来很方便,直接插起来就可以用




这块屏幕更详尽的介绍
然后树莓派
感觉这货没什么好说的,大家应该都知道,稍微说一下
这是一个迷人有趣的Linux电脑
树莓派(为学生计算机编程教育设计的一种卡片式电脑)编辑 Raspberry Pi(中文名为“树莓派”,简写为RPi,或者RasPi/RPi)是为学生计算机编程教育而设计,只有信用卡大小的卡片式电脑,其系统基于Linux。 随着Windows 10 IoT的发布,我们也将可以用上运行Windows的树莓派。 自问世以来,受众多计算机发烧友和创客的追捧,曾经一“派”难求。别看其外表“娇小”,内“心”却很强大,视频、音频等功能通通皆有,可谓是“麻雀虽小,五脏俱全”。
树莓派由注册于英国的慈善组织“Raspberry Pi 基金会”开发,Eben·Upton/埃·厄普顿为项目带头人。2012年3月,英国剑桥大学埃本·阿普顿(Eben Epton)正式发售世界上最小的台式机,又称卡片式电脑,外形只有信用卡大小,却具有电脑的所有基本功能,这就是Raspberry Pi电脑板,中文译名"树莓派"。这一基金会以提升学校计算机科学及相关学科的教育,让计算机变得有趣为宗旨。基金会期望这 一款电脑无论是在发展中国家还是在发达国家,会有更多的其它应用不断被开发出来,并应用到更多领域。在2006年树莓派早期概念是基于Atmel的 ATmega644单片机,首批上市的10000“台”树莓派的“板子”,由中国台湾和大陆厂家制造。
树莓派名字中的pi其实指的就是 python
所以我选择了 python 作为 镜子的编程语言那么说说我用python在这上面干了些什么
事实上最开始我的策略使用一个全屏的网页浏览器显示一个 黑底白字 的网站
可是坑爹的是 我更不不会web技术
然后我就打算要不试试python吧,本来还觉得不爽又要新学一门语言
但是python给我很大的惊喜
我并没有学习python的语法,而是看了两个例子就直接使用tkinter库开始编程
这就是python的优势: 简单
接触python到用tk写出第一个的界面,只用了1个小时的时间
就是一开始那个环形显示时间那个
对于准大一新生来说,不管是python的语法还是库的使用都很容易,所以python很适合用来入门
我甚至打算教我的女朋友(nue)(gou)

所有的界面都是黑底白字。


所以我开发了一个类,能让这些元素拥有动画效果,并且能让 Pm2.5 天气 时间 我和女朋友在一起了多少秒 等等 这些信息能够随机的在镜子上淡入淡出

我是比较偏向语音这个选择,因为这将会是一种新式的交互体验,就跟童话里的魔镜一样,我对这个镜子的定位是一个外形比较骚的公众信息聚合平台,所以语音相对于手机来说,更方便,而对于这样一个定位来讲,方便很重要,试想你在酒店想要找厕所,然后你问魔镜 ’魔镜魔镜,厕所在哪‘ 是不是比掏出手机链结魔镜,然后再用某种低效的输入进行交互方便的多?
再说百度等都有开放的API可以用何乐而不为?
所以下一步的目标就是把语音的功能开发出来,目前卡在了语音采集这个问题上。
还希望大神多指教
单位提供盒饭,不过需要自己前一天到内网的订餐页面订餐。有一天我忘了订餐,只好自己花钱订外卖了。实现的功能是查看把自己删了的微信好友,原理就是新建群组,用的是微信网页版的接口,如果加不进来就是被删好友了(不要在群组里讲话,别人是看不见的)
对了,这个用的是python2.x开发的,python3.x是运行不了的
这个是应用的Github界面
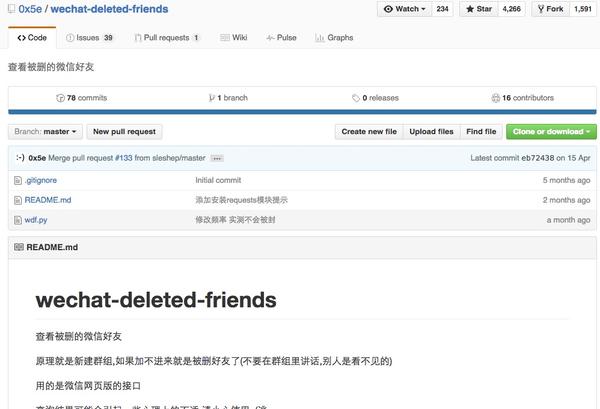
这个是运行之后的结果,会让你用微信扫一个二维码,然后就可以了
 脑洞打开的小工具到没怎么写过,但是写了一个挑逗女神的一个小程序!!!
脑洞打开的小工具到没怎么写过,但是写了一个挑逗女神的一个小程序!!!- <code class="language-python"><span class="c">#!/usr/bin/env python2.7</span>
- <span class="c"># --*-- encoding: utf-8 --*--</span>
- <span class="c"># enable print(,end='')</span>
- <span class="c">#from __future__ import print_function </span>
- <span class="kn">import</span> <span class="nn">argparse</span>
- <span class="kn">import</span> <span class="nn">sys</span>
- <span class="kn">import</span> <span class="nn">os</span>
- <span class="kn">import</span> <span class="nn">re</span>
- <span class="kn">import</span> <span class="nn">bs4</span>
- <span class="kn">import</span> <span class="nn">urlparse</span>
- <span class="kn">import</span> <span class="nn">requests</span>
- <span class="k">def</span> <span class="nf">download</span><span class="p">(</span><span class="n">url</span><span class="p">,</span> <span class="n">out</span><span class="p">,</span> <span class="n">title</span><span class="p">):</span>
- <span class="c">#out = url.split('/')[-1]</span>
- <span class="n">resp</span> <span class="o">=</span> <span class="n">requests</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">url</span><span class="p">,</span> <span class="n">stream</span><span class="o">=</span><span class="bp">True</span><span class="p">)</span>
- <span class="k">if</span> <span class="n">resp</span><span class="o">.</span><span class="n">status_code</span> <span class="o">!=</span> <span class="n">requests</span><span class="o">.</span><span class="n">codes</span><span class="o">.</span><span class="n">ok</span><span class="p">:</span>
- <span class="k">return</span> <span class="bp">False</span>
- <span class="n">total</span> <span class="o">=</span> <span class="n">resp</span><span class="o">.</span><span class="n">headers</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="s">'content-length'</span><span class="p">)</span>
- <span class="k">if</span> <span class="n">total</span> <span class="ow">is</span> <span class="bp">None</span><span class="p">:</span>
- <span class="n">total</span> <span class="o">=</span> <span class="mi">0</span>
- <span class="k">else</span><span class="p">:</span>
- <span class="n">total</span> <span class="o">=</span> <span class="nb">int</span><span class="p">(</span><span class="n">total</span><span class="p">)</span>
- <span class="k">def</span> <span class="nf">show_progress</span><span class="p">(</span><span class="n">total</span><span class="p">,</span> <span class="n">acc</span><span class="p">):</span>
- <span class="k">if</span> <span class="n">total</span> <span class="o">==</span> <span class="mi">0</span><span class="p">:</span>
- <span class="n">sys</span><span class="o">.</span><span class="n">stdout</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s">"{} ?</span><span class="se">\r</span><span class="s">"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">out</span><span class="p">))</span>
- <span class="k">else</span><span class="p">:</span>
- <span class="c">#sys.stdout.write("{} [ {:3d}% ]\r".format(100*acc/total, out))</span>
- <span class="n">sys</span><span class="o">.</span><span class="n">stdout</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s">"{} </span><span class="se">\"</span><span class="s">{}</span><span class="se">\"</span><span class="s"> {:3d}%</span><span class="se">\r</span><span class="s">"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">title</span><span class="p">,</span> <span class="n">out</span><span class="p">,</span> <span class="mi">100</span><span class="o">*</span><span class="n">acc</span><span class="o">/</span><span class="n">total</span><span class="p">))</span>
- <span class="n">sys</span><span class="o">.</span><span class="n">stdout</span><span class="o">.</span><span class="n">flush</span><span class="p">()</span>
- <span class="n">acc</span> <span class="o">=</span> <span class="mi">0</span>
- <span class="n">show_progress</span><span class="p">(</span><span class="n">total</span><span class="p">,</span> <span class="n">acc</span><span class="p">)</span>
- <span class="k">with</span> <span class="nb">open</span><span class="p">(</span><span class="n">out</span><span class="p">,</span> <span class="s">'wb'</span><span class="p">)</span> <span class="k">as</span> <span class="n">f</span><span class="p">:</span>
- <span class="k">for</span> <span class="n">chunk</span> <span class="ow">in</span> <span class="n">resp</span><span class="o">.</span><span class="n">iter_content</span><span class="p">(</span><span class="n">chunk_size</span><span class="o">=</span><span class="mi">1024</span><span class="p">):</span>
- <span class="k">if</span> <span class="n">chunk</span><span class="p">:</span> <span class="c"># filter out keep-alive new chunks</span>
- <span class="n">f</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">chunk</span><span class="p">)</span>
- <span class="n">f</span><span class="o">.</span><span class="n">flush</span><span class="p">()</span>
- <span class="n">acc</span> <span class="o">+=</span> <span class="nb">len</span><span class="p">(</span><span class="n">chunk</span><span class="p">)</span>
- <span class="n">show_progress</span><span class="p">(</span><span class="n">total</span><span class="p">,</span> <span class="n">acc</span><span class="p">)</span>
- <span class="n">sys</span><span class="o">.</span><span class="n">stdout</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="s">"</span><span class="se">\n</span><span class="s">"</span><span class="p">)</span>
- <span class="k">return</span> <span class="bp">True</span>
- <span class="k">def</span> <span class="nf">fetch</span><span class="p">(</span><span class="n">from_url</span><span class="p">,</span> <span class="n">offset</span><span class="p">,</span> <span class="n">count</span><span class="p">):</span>
- <span class="k">with</span> <span class="nb">open</span><span class="p">(</span><span class="n">from_url</span><span class="p">,</span> <span class="s">"r"</span><span class="p">)</span> <span class="k">as</span> <span class="n">f</span><span class="p">:</span>
- <span class="n">html</span> <span class="o">=</span> <span class="n">f</span><span class="o">.</span><span class="n">read</span><span class="p">()</span>
- <span class="n">soup</span> <span class="o">=</span> <span class="n">bs4</span><span class="o">.</span><span class="n">BeautifulSoup</span><span class="p">(</span><span class="n">html</span><span class="p">)</span>
- <span class="c"># get title</span>
- <span class="n">content</span> <span class="o">=</span> <span class="n">soup</span><span class="o">.</span><span class="n">find_all</span><span class="p">(</span><span class="s">"h2"</span><span class="p">,</span> <span class="n">class_</span><span class="o">=</span><span class="s">"first"</span><span class="p">)</span>
- <span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="n">content</span><span class="p">)</span> <span class="o">==</span> <span class="mi">0</span><span class="p">:</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"title not found!"</span><span class="p">)</span>
- <span class="k">return</span>
- <span class="k">elif</span> <span class="nb">len</span><span class="p">(</span><span class="n">content</span><span class="p">)</span> <span class="o">!=</span> <span class="mi">1</span><span class="p">:</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"title not unique!"</span><span class="p">)</span>
- <span class="n">fdir</span> <span class="o">=</span> <span class="n">content</span><span class="p">[</span><span class="mi">0</span><span class="p">]</span><span class="o">.</span><span class="n">contents</span><span class="p">[</span><span class="mi">0</span><span class="p">]</span><span class="o">.</span><span class="n">encode</span><span class="p">(</span><span class="s">"utf8"</span><span class="p">)</span><span class="o">.</span><span class="n">strip</span><span class="p">()</span><span class="o">.</span><span class="n">replace</span><span class="p">(</span><span class="s">"–"</span><span class="p">,</span> <span class="s">"-"</span><span class="p">)</span>
- <span class="k">if</span> <span class="ow">not</span> <span class="n">os</span><span class="o">.</span><span class="n">path</span><span class="o">.</span><span class="n">exists</span><span class="p">(</span><span class="n">fdir</span><span class="p">):</span>
- <span class="n">os</span><span class="o">.</span><span class="n">mkdir</span><span class="p">(</span><span class="n">fdir</span><span class="p">)</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"mkdir: </span><span class="se">\"</span><span class="s">{}</span><span class="se">\"</span><span class="s">"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">fdir</span><span class="p">))</span>
- <span class="c"># get image url</span>
- <span class="n">content</span> <span class="o">=</span> <span class="n">soup</span><span class="o">.</span><span class="n">find_all</span><span class="p">(</span><span class="s">"div"</span><span class="p">,</span> <span class="nb">id</span><span class="o">=</span><span class="n">re</span><span class="o">.</span><span class="n">compile</span><span class="p">(</span><span class="s">"^post-"</span><span class="p">))</span>
- <span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="n">content</span><span class="p">)</span> <span class="o">==</span> <span class="mi">0</span><span class="p">:</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"target not found!"</span><span class="p">)</span>
- <span class="k">return</span>
- <span class="k">elif</span> <span class="nb">len</span><span class="p">(</span><span class="n">content</span><span class="p">)</span> <span class="o">!=</span> <span class="mi">1</span><span class="p">:</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"target not unique!"</span><span class="p">)</span>
- <span class="n">imgs</span> <span class="o">=</span> <span class="n">content</span><span class="p">[</span><span class="mi">0</span><span class="p">]</span><span class="o">.</span><span class="n">find_all</span><span class="p">(</span><span class="s">"img"</span><span class="p">)</span>
- <span class="n">start</span> <span class="o">=</span> <span class="mi">0</span> <span class="k">if</span> <span class="n">offset</span> <span class="ow">is</span> <span class="bp">None</span> <span class="k">else</span> <span class="n">offset</span>
- <span class="n">end</span> <span class="o">=</span> <span class="nb">len</span><span class="p">(</span><span class="n">imgs</span><span class="p">)</span> <span class="k">if</span> <span class="n">count</span> <span class="ow">is</span> <span class="bp">None</span> <span class="k">else</span> <span class="p">(</span><span class="n">start</span><span class="o">+</span><span class="n">count</span><span class="p">)</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"# of image: {}"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">nimg</span><span class="p">))</span>
- <span class="k">for</span> <span class="n">idx</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="n">start</span><span class="p">,</span> <span class="n">end</span><span class="p">):</span>
- <span class="n">img</span> <span class="o">=</span> <span class="n">imgs</span><span class="p">[</span><span class="n">idx</span><span class="p">]</span>
- <span class="n">url</span> <span class="o">=</span> <span class="nb">str</span><span class="p">(</span><span class="n">img</span><span class="o">.</span><span class="n">attrs</span><span class="p">[</span><span class="s">"src"</span><span class="p">])</span>
- <span class="c">#url = url.replace("http://t10", "http://i10")</span>
- <span class="n">url</span> <span class="o">=</span> <span class="n">url</span><span class="o">.</span><span class="n">replace</span><span class="p">(</span><span class="s">"http://t"</span><span class="p">,</span> <span class="s">"http://i"</span><span class="p">)</span>
- <span class="n">ext</span> <span class="o">=</span> <span class="n">url</span><span class="p">[</span><span class="n">url</span><span class="o">.</span><span class="n">rfind</span><span class="p">(</span><span class="s">"."</span><span class="p">):]</span>
- <span class="n">out</span> <span class="o">=</span> <span class="s">"{0}/{1}{2}"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">fdir</span><span class="p">,</span> <span class="n">idx</span><span class="o">+</span><span class="mi">1</span><span class="p">,</span> <span class="n">ext</span><span class="p">)</span>
- <span class="c"># get image file</span>
- <span class="k">for</span> <span class="n">retry</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="mi">0</span><span class="p">,</span> <span class="mi">5</span><span class="p">):</span>
- <span class="n">title</span> <span class="o">=</span> <span class="p">(</span><span class="s">"({{:{}d}}/{{}})"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="nb">len</span><span class="p">(</span><span class="nb">str</span><span class="p">(</span><span class="n">end</span><span class="p">)))</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">idx</span><span class="o">+</span><span class="mi">1</span><span class="p">,</span> <span class="n">end</span><span class="p">))</span>
- <span class="k">if</span> <span class="n">download</span><span class="p">(</span><span class="n">url</span><span class="p">,</span> <span class="n">out</span><span class="p">,</span> <span class="n">title</span><span class="p">):</span>
- <span class="k">break</span>
- <span class="k">print</span><span class="p">(</span><span class="s">"failed, try again ({})"</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">retry</span><span class="o">+</span><span class="mi">1</span><span class="p">))</span>
- <span class="k">def</span> <span class="nf">main</span><span class="p">():</span>
- <span class="n">parser</span> <span class="o">=</span> <span class="n">argparse</span><span class="o">.</span><span class="n">ArgumentParser</span><span class="p">(</span><span class="n">description</span><span class="o">=</span><span class="s">'nah'</span><span class="p">)</span>
- <span class="n">parser</span><span class="o">.</span><span class="n">add_argument</span><span class="p">(</span><span class="s">'urls'</span><span class="p">,</span> <span class="nb">type</span><span class="o">=</span><span class="nb">str</span><span class="p">,</span> <span class="n">nargs</span><span class="o">=</span><span class="s">"+"</span><span class="p">,</span> <span class="n">help</span><span class="o">=</span><span class="s">'Specify URLs'</span><span class="p">)</span>
- <span class="n">parser</span><span class="o">.</span><span class="n">add_argument</span><span class="p">(</span><span class="s">'--offset'</span><span class="p">,</span> <span class="nb">type</span><span class="o">=</span><span class="nb">int</span><span class="p">,</span> <span class="n">nargs</span><span class="o">=</span><span class="s">"?"</span><span class="p">,</span> <span class="n">help</span><span class="o">=</span><span class="s">'offset'</span><span class="p">)</span>
- <span class="n">parser</span><span class="o">.</span><span class="n">add_argument</span><span class="p">(</span><span class="s">'--count'</span><span class="p">,</span> <span class="nb">type</span><span class="o">=</span><span class="nb">int</span><span class="p">,</span> <span class="n">nargs</span><span class="o">=</span><span class="s">"?"</span><span class="p">,</span> <span class="n">help</span><span class="o">=</span><span class="s">'count'</span><span class="p">)</span>
- <span class="n">args</span> <span class="o">=</span> <span class="n">parser</span><span class="o">.</span><span class="n">parse_args</span><span class="p">()</span>
- <span class="k">for</span> <span class="n">url</span> <span class="ow">in</span> <span class="n">args</span><span class="o">.</span><span class="n">urls</span><span class="p">:</span>
- <span class="n">fetch</span><span class="p">(</span><span class="n">url</span><span class="p">,</span> <span class="n">args</span><span class="o">.</span><span class="n">offset</span><span class="p">,</span> <span class="n">args</span><span class="o">.</span><span class="n">count</span><span class="p">)</span>
- <span class="k">if</span> <span class="n">__name__</span> <span class="o">==</span> <span class="s">"__main__"</span><span class="p">:</span>
- <span class="n">main</span><span class="p">()</span>
- </code>
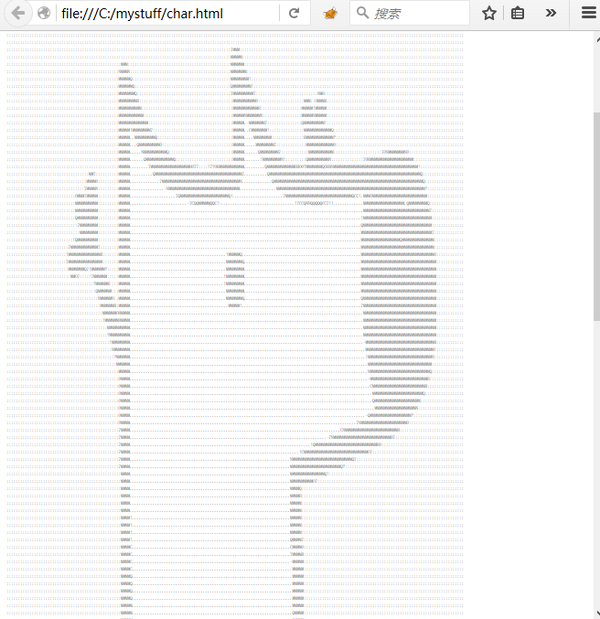

- <code class="language-python"><span class="kn">import</span> <span class="nn">Image</span>
-
- <span class="n">color</span> <span class="o">=</span> <span class="s">'MNHQ$OC?7>!:-;.'</span> <span class="c">#zifu</span>
-
- <span class="k">def</span> <span class="nf">to_html</span><span class="p">(</span><span class="n">func</span><span class="p">):</span>
- <span class="n">html_head</span> <span class="o">=</span> <span class="s">'''</span>
- <span class="s"> </span>
- <span class="s"> </span>
- <span class="s"> <style type="text/css"></span>
- <span class="s"> body {font-family:Monospace; font-size:5px;}</span>
- <span class="s"> </style></span>
- <span class="s"> </span>
- <span class="s"> '''</span>
- <span class="n">html_tail</span> <span class="o">=</span> <span class="s">''</span>
- <span class="c"># ding yi HTML</span>
- <span class="k">def</span> <span class="nf">wrapper</span><span class="p">(</span><span class="n">img</span><span class="p">):</span>
- <span class="n">pic_str</span> <span class="o">=</span> <span class="n">func</span><span class="p">(</span><span class="n">img</span><span class="p">)</span>
- <span class="n">pic_str</span> <span class="o">=</span> <span class="s">''</span><span class="o">.</span><span class="n">join</span><span class="p">(</span><span class="n">l</span> <span class="o">+</span> <span class="s">' <br>'</span> <span class="k">for</span> <span class="n">l</span> <span class="ow">in</span> <span class="n">pic_str</span><span class="o">.</span><span class="n">splitlines</span><span class="p">())</span>
- <span class="k">return</span> <span class="n">html_head</span> <span class="o">+</span> <span class="n">pic_str</span> <span class="o">+</span> <span class="n">html_tail</span>
-
- <span class="k">return</span> <span class="n">wrapper</span>
- <span class="c"># fan hui zhi</span>
- <span class="nd">@to_html</span>
- <span class="k">def</span> <span class="nf">make_char_img</span><span class="p">(</span><span class="n">img</span><span class="p">):</span>
- <span class="n">pix</span> <span class="o">=</span> <span class="n">img</span><span class="o">.</span><span class="n">load</span><span class="p">()</span>
- <span class="n">pic_str</span> <span class="o">=</span> <span class="s">''</span>
- <span class="n">width</span><span class="p">,</span> <span class="n">height</span> <span class="o">=</span> <span class="n">img</span><span class="o">.</span><span class="n">size</span>
- <span class="k">for</span> <span class="n">h</span> <span class="ow">in</span> <span class="nb">xrange</span><span class="p">(</span><span class="n">height</span><span class="p">):</span>
- <span class="k">for</span> <span class="n">w</span> <span class="ow">in</span> <span class="nb">xrange</span><span class="p">(</span><span class="n">width</span><span class="p">):</span>
- <span class="n">pic_str</span> <span class="o">+=</span> <span class="n">color</span><span class="p">[</span><span class="nb">int</span><span class="p">(</span><span class="n">pix</span><span class="p">[</span><span class="n">w</span><span class="p">,</span> <span class="n">h</span><span class="p">])</span> <span class="o">*</span> <span class="mi">14</span> <span class="o">/</span> <span class="mi">255</span><span class="p">]</span>
- <span class="n">pic_str</span> <span class="o">+=</span> <span class="s">'</span><span class="se">\n</span><span class="s">'</span>
- <span class="k">return</span> <span class="n">pic_str</span>
-
- <span class="k">def</span> <span class="nf">preprocess</span><span class="p">(</span><span class="n">img_name</span><span class="p">):</span>
- <span class="n">img</span> <span class="o">=</span> <span class="n">Image</span><span class="o">.</span><span class="n">open</span><span class="p">(</span><span class="n">img_name</span><span class="p">)</span>
-
- <span class="n">w</span><span class="p">,</span> <span class="n">h</span> <span class="o">=</span> <span class="n">img</span><span class="o">.</span><span class="n">size</span>
- <span class="n">m</span> <span class="o">=</span> <span class="nb">max</span><span class="p">(</span><span class="n">img</span><span class="o">.</span><span class="n">size</span><span class="p">)</span>
- <span class="n">delta</span> <span class="o">=</span> <span class="n">m</span> <span class="o">/</span> <span class="mf">200.0</span>
- <span class="n">w</span><span class="p">,</span> <span class="n">h</span> <span class="o">=</span> <span class="nb">int</span><span class="p">(</span><span class="n">w</span> <span class="o">/</span> <span class="n">delta</span><span class="p">),</span> <span class="nb">int</span><span class="p">(</span><span class="n">h</span> <span class="o">/</span> <span class="n">delta</span><span class="p">)</span>
- <span class="n">img</span> <span class="o">=</span> <span class="n">img</span><span class="o">.</span><span class="n">resize</span><span class="p">((</span><span class="n">w</span><span class="p">,</span> <span class="n">h</span><span class="p">))</span>
- <span class="n">img</span> <span class="o">=</span> <span class="n">img</span><span class="o">.</span><span class="n">convert</span><span class="p">(</span><span class="s">'L'</span><span class="p">)</span>
-
- <span class="k">return</span> <span class="n">img</span>
-
- <span class="k">def</span> <span class="nf">save_to_file</span><span class="p">(</span><span class="n">filename</span><span class="p">,</span> <span class="n">pic_str</span><span class="p">):</span>
- <span class="n">outfile</span> <span class="o">=</span> <span class="nb">open</span><span class="p">(</span><span class="n">filename</span><span class="p">,</span> <span class="s">'w'</span><span class="p">)</span>
- <span class="n">outfile</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="n">pic_str</span><span class="p">)</span>
- <span class="n">outfile</span><span class="o">.</span><span class="n">close</span><span class="p">()</span>
-
- <span class="k">def</span> <span class="nf">main</span><span class="p">():</span>
- <span class="n">img</span> <span class="o">=</span> <span class="n">preprocess</span><span class="p">(</span><span class="nb">raw_input</span><span class="p">(</span><span class="s">'input your filename:'</span><span class="p">))</span>
- <span class="n">pic_str</span> <span class="o">=</span> <span class="n">make_char_img</span><span class="p">(</span><span class="n">img</span><span class="p">)</span>
- <span class="n">save_to_file</span><span class="p">(</span><span class="s">'char.html'</span><span class="p">,</span> <span class="n">pic_str</span><span class="p">)</span>
-
- <span class="k">if</span> <span class="n">__name__</span> <span class="o">==</span> <span class="s">'__main__'</span><span class="p">:</span>
- <span class="n">main</span><span class="p">()</span>
- </code>