先随便扯扯。对于当前的 Web 而言,HTML 是联系大多数 Web 资源的纽带,也是内容的载体。在 Web 被刚刚设计出来的时候,Tim Berners-Lee 可能不会想到它现在会达到的规模以及深入到我们生活的那么多方面。也许起初的想法很简单:用来发布 Web 内容和资源的索引,方便人们查看。
但是随着 Web 规模的不断扩大,信息量之大已经不在人肉处理的范围之内了。这个时候人们开始用机器来处理 Web 上发布的各种内容,搜索引擎就诞生了。再后来,人们又设计了各种智能程序来对索引好的内容作各种处理和挖掘。所以让机器能够更好地读懂 Web 上发布的各种内容就变得越来越重要。
其实 HTML 在刚开始设计出来的时候就是带有一定的「语义」的,包括段落、表格、图片、标题等等,但这些更多地只是方便浏览器等 UA 对它们作合适的处理。但逐渐地,机器也要借助 HTML 提供的语义以及自然语言处理的手段来「读懂」它们从网上获取的 HTML 文档,但它们无法读懂例如「红色的文字」或者是深度嵌套的表格布局中内容的含义,因为太多已有的内容都是专门为了可视化的浏览器设计的。面对这种情况,出现了两种观点:
我们可以让机器的理解能力越来越接近人类,人能看懂、听懂的东西,机器也能理解;
我们应该在发布内容的时候,就用机器可读的、被广泛认可的语义信息来描述内容,来降低机器处理 Web 内容的难度(HTML 本身就已经是朝这个方向迈出的一小步了)。
我画的这个图,意思是说,内容的语义表达能力和 AI 的智能程度决定了机器分析处理 Web 内容能力的高低。上面观点 1 的方向是朝着人类水平的人工智能努力,而观点 2 的方向正是万维网创始人 Tim Berners-Lee 爵士提出的美好愿景:语义网。语义网我就不多说了,简单来说就是让一切内容和包括对关系的描述都成为 Web 上的资源,都可以由唯一的 URI 定义,语义明确、机器可读。显然,两条路都的终极目标都很遥远,第一条路技术上难以实现,而第二条路实施起来障碍太多。
我认为我们当前能够看得见摸得着的 Web 语义化,其实就是在往第二条路的方向上,迈出的一小步,即对已经有的被广泛认可的 HTML 标准做改进。我们刚开始意识到,我们必须回归内容本身,将内容本身的语义合理地表述出来,再为不同的用户代理设计不同的样式描述,也就是我们说的内容与样式分离。这样我们在提供内容的时候,首先要做的就是将内容本身进行合理的描述,暂时不用考虑它的最终呈现会是什么样子。
HTML 规范其实一直在往语义化的方向上努力,许多元素、属性在设计的时候,就已经考虑了如何让各种用户代理甚至网络爬虫更好地理解 HTML 文档。HTML5 更是在之前规范的基础上,将所有表现层(presentational)的语义描述都进行了修改或者删除,增加了不少可以表达更丰富语义的元素。为什么这样的语义元素是有意义的?因为它们被广泛认可。所谓语义本身就是对符号的一种共识,被认可的程度越高、范围越广,人们就越可以依赖它实现各种各样的功能。
HTML5 并非 Web 语义唯一倚仗的规范,除了 W3C 和 WHATWG 外,还有其它的组织在为扩展、标准化 Web 语义做着贡献。只要有浏览器厂商、搜索引擎原意支持,它们的规范一样可以成为通用的基础设施。例如 microformats 社区以及 http://Schema.org 上都有对 HTML 以及 Microdata(http://www.w3.org/TR/html5/microdata.html) 规范的扩展词汇表,Google、Bing、Yahoo! 等搜索引擎以及各个主流浏览器都不同程度地接纳了其中定义的语义扩展,并应用在了生产中。
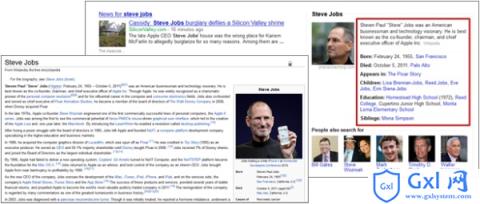
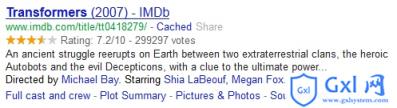
下面举两个 Google 应用扩展语义的例子。 Google 的搜索结果,可以根据 microformats 的 hCard 语法从抓取的页面识别出人物信息: 也可通过网页内嵌的 Microdata 数据读取作品评分等信息: 关于 HTML5 的各个元素语义的描述,我之前做过一份 slides,上面提到的例子都是那里面的,也可以参考一下:Semantic HTML(http://justineo.github.com/slideshows/semantic-html/)。
首先需要注意,本人回答一向漏洞百出,请意会。
3、W3C组织意识到了之前HTML版本的不足,推出的HTML5进一步推进了Web语义化发展,采用了诸如footer、section等语义化标签,弥补了采用id="footer"或者class="footer"形式的不足,以更好的推动Web的发展。
说一下个人的愚见:所谓 web 语义化,从广义上来说,不仅要使机器(搜索引擎等)易于理解,也要使人易于理解。在团队协作开发中,对人的易于理解显得尤为重要了,一个莫名其妙的 class 会让后续的开发或者维护者一头雾水,增加了协作成本。
具体来说,就是在书写html时,尽量使用具有语义信息的标签,例如header,nav,aside,section等代替那些没有语义信息的标签,例如big,center,strike,font等(完全可以用css来取代的标签)。这样不仅有利于页面DOM的组织,也有利于机器(主要是搜索引擎)的理解。 而语义网的目标就是为了使得网络上的信息更加容易被机器理解和查找,从而提升人类使用网络获取信息的体验。
其实 html 文档和 word 文档本质上没什么区别,只不过是 html 可以使用 css/js 为其附加样式和交互,并且能够在互联网上快速传播而已。所以在写 html 的时候也要像写 word 文档一样,标题就是标题,段落就是段落,图片就是图片,列表就是列表,表格就是表格,不要啥都用 div、span 这种什么都是又什么都不是的无语义的标签来描述。看一张网页是否符合语义化,只要把它所有的 css 文件都拿掉后是否还能结构分明、阅读顺畅。
当然这还只是 html 标记的语义化, @斯迪 也提到了css的ID、class名同样也应该具有语义化。同时语义化还有从抽象到具体的概念,比如:内容>列表>有序列表>排行榜,html只能描述到抽象的语义,具体的语义就需要 css 的ID、class名去补充了。
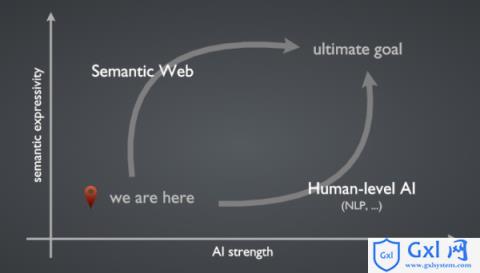
 我画的这个图,意思是说,内容的语义表达能力和 AI 的智能程度决定了机器分析处理 Web 内容能力的高低。上面观点 1 的方向是朝着人类水平的人工智能努力,而观点 2 的方向正是万维网创始人 Tim Berners-Lee 爵士提出的美好愿景:语义网。语义网我就不多说了,简单来说就是让一切内容和包括对关系的描述都成为 Web 上的资源,都可以由唯一的 URI 定义,语义明确、机器可读。显然,两条路都的终极目标都很遥远,第一条路技术上难以实现,而第二条路实施起来障碍太多。
我画的这个图,意思是说,内容的语义表达能力和 AI 的智能程度决定了机器分析处理 Web 内容能力的高低。上面观点 1 的方向是朝着人类水平的人工智能努力,而观点 2 的方向正是万维网创始人 Tim Berners-Lee 爵士提出的美好愿景:语义网。语义网我就不多说了,简单来说就是让一切内容和包括对关系的描述都成为 Web 上的资源,都可以由唯一的 URI 定义,语义明确、机器可读。显然,两条路都的终极目标都很遥远,第一条路技术上难以实现,而第二条路实施起来障碍太多。