distinct
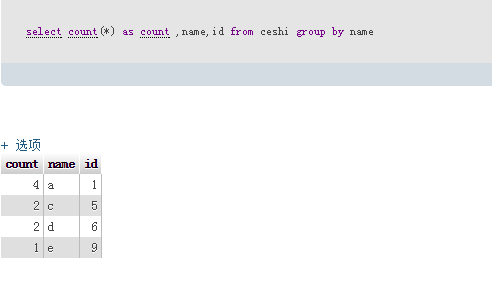
如果要保留id的最小值,例如: 数据: 执行sql:select count(*) as count ,name,id from ceshi group by name 最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
如果想保留id的最大值: 简单的办法是:delete from ceshi where id not in (select count(*) as count ,name,id from (select * from ceshi order by id desc) group by name)
distinct
其实非常的简单,只需要把你这张表当成两张表来处理就行了。 DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id < p2.id; 这里有个问题,题主说保留最新的那一条(也就是ID最小的那个),既然是递增,最新的不应该是最大的那条吗? 上面的的语句,p1.id < p2.id,所以获取到的是id最大的,因为p1.id小于p2.id就会被删除,只有最大的值不满足。如果要获取id最小的那个,只需要把'<'改成'>'即可。 当然是用group by,count可以更精准控制重复n次的情况。不过目测楼主需求应该只要把重复的删掉,保留最新的就可以了。
DELETE FROM table WHERE id not in ( SELECT tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… ); table是表名,field是要去重的字段。
新建一个表,设置name,email为唯一索引,然后重新插入旧表数据